The Web Scraping Club | Pierluigi Vinciguerra | Substack
Excerpt
News, solutions and interviews about web scraping. In this substack you will find weekly content about:
- Web Scraping techniques
- Interviews with key people in the industry
- Anti bot infos and counter measures
- Real world examples and code. Click to read The Web Scraping Club, by Pierluigi Vinciguerra, a Substack publication with thousands of subscribers.
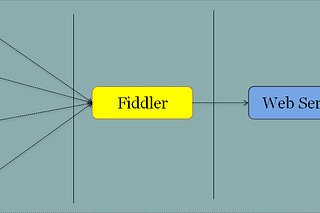
The Lab #52: Scraping with LLMs and ScrapeGraphAi - part 1
Are LLMs the Holy Graal for web scraping?
May 30 •
1

The Lab #51: APIs with Bearer Token
Scraping data from API endpoints requiring Bearer Token
May 17 •
1

Celebrating the 50th article of The Lab series
A brief review of the first 50 episodes of The Lab series
May 10 •
3

The Lab #49: Bypassing Cloudflare with open source repositories
And my two cents about these solutions
May 3 •
1

The Lab #48: Scraping with AWS Lambda
Using Serverless and Selenium on Lambda for gathering data
Apr 12 •
2
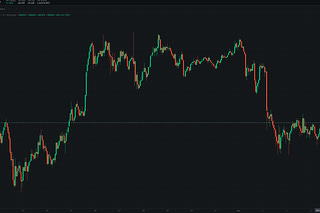
The Lab #47: Scraping real time data with Python
Using WebSocket to scrape data from Bitstamp and Sofascore
Apr 4 •
3
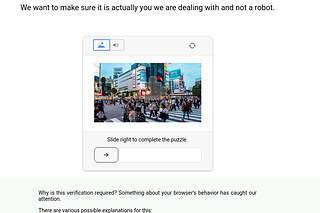
The Lab #46: Fingerprint injection in Playwright
A home-made solution to bypass anti-bots by changing your browser fingerprint.
Mar 29 •
2
THE LAB #45: Bypassing Geo-fencing While Scraping
How to scrape websites that are banned in your country
Mar 22 •
2

The Lab #44: Scraping the dark web
Scraping the dark web with Playwright and Brave
Mar 7 •
2

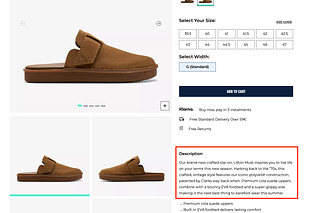
The Lab #43: Scraping inventory data: why, how and where
How to use web scraping to get inventory data and estimate sales
Feb 29 •
2
[
3
](https://substack.thewebscraping.club/p/scraping-inventory-data/comments)
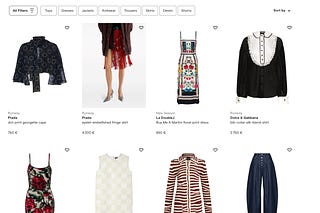
The Lab #42: Bypassing PerimeterX without a browser automation tool
Bypassing PerimeterX with free tools and without running a browser
Feb 23 •

The Lab #41: Scrapoxy, the super proxy aggregator
How to use Scrapoxy in your web scraping architecture
Feb 15 •
3

The Lab #40: start a web data monetization project with Data Boutique
Buying and selling high-quality web data has never been so easy.
Feb 8 •
4

The Lab #39: Mouse movements in Playwright
How to move the mouse in Playwright to mimic human behavior
Feb 1 •
3
[
2
](https://substack.thewebscraping.club/p/bypass-datadome-mouse-movements-in-playwright/comments)

The Lab #38: Bypassing Kasada for web scraping 2024 edition
Another articles with tools and techniques to bypass an anti-bot
Jan 25 •
[
2
](https://substack.thewebscraping.club/p/bypassing-kasada-web-scraping/comments)
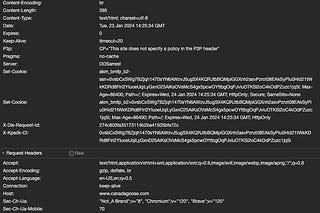
The Lab #37: Bypassing Cloudflare with anti-detect browsers - Part 2
Using Kameleo to bypass Cloudflare bot detection
Jan 18 •
5
[
1
](https://substack.thewebscraping.club/p/bypassing-cloudflare-with-kameleo/comments)

The Lab #36: Bypassing Cloudflare with anti-detect browsers
Configuring GoLogin to bypass Cloudflare bot detection
Jan 11 •
2
What to expect from The Lab posts in 2024
Why I’m writing the “The Lab” articles and what to expect this new year
Jan 4 •
1

The Lab #35: Bypassing PerimeterX with Python and Playwright
Bypassing Perimeterx with free Python tools in 2023.
Dec 21, 2023 •
The Lab #34: Bypassing Datadome - End of 2023 Version
Is it possible to bypass Datadome today?
Dec 6, 2023 •
2
[
3
](https://substack.thewebscraping.club/p/bypassing-datadome-2023-scraping/comments)
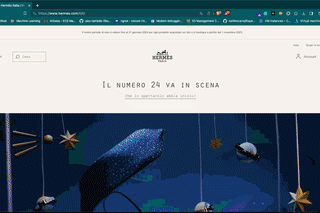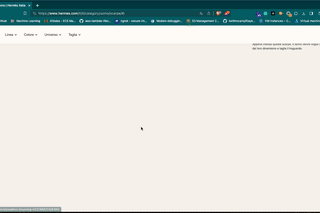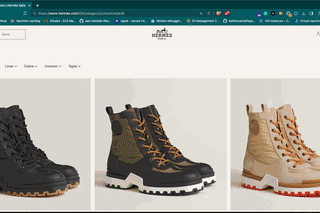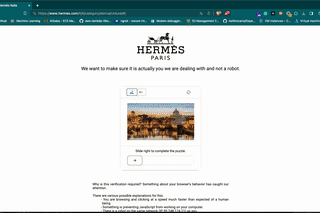
THE LAB 33: Fingerprinting at different connection layers
How to create and test a scraper with a coherent fingerprint between the different layers
Nov 30, 2023 •
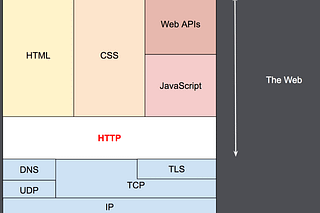
THE LAB 32: hRequests vs anti-bots: a full benchmark
How does it perform against Cloudflare, Akamai, Datadome, PerimeterX and Kasada?
Nov 24, 2023 •
4

THE LAB #31: Scraping location data using a world grid
Building a fundamental tool for scraping location data in a cost-effective way
Nov 9, 2023 •
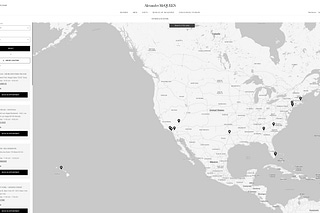
THE LAB #30: How to bypass Akamai protected website when nothing else works
And without paying any commercial solution. An ode to trivial solutions.
Oct 27, 2023 •
1
[
1
](https://substack.thewebscraping.club/p/the-lab-30-how-to-bypass-akamai-protected/comments)

THE LAB #29: Bypass Cloudflare Bot Protection with Scrapy
Is it possible to bypass Cloudflare without using an headful browser?
Oct 13, 2023 •
2
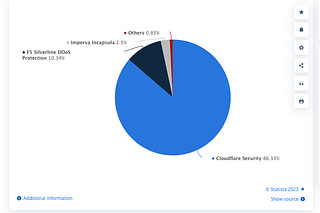
THE LAB #28: Deep dive on inventory levels tracking
A real world example of scraping inventory level from an heavily Akamai-protected website
Sep 28, 2023 •
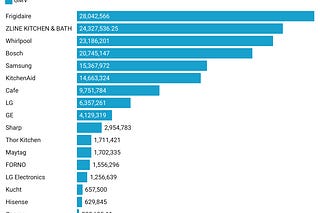
THE LAB #27: Inventory levels, the holy grail of web scraped data
How web scraping could give advantage in estimating the revenues of companies
Sep 14, 2023 •
1
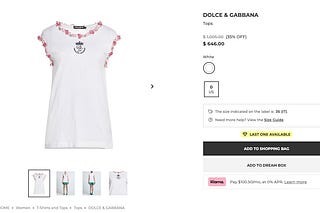
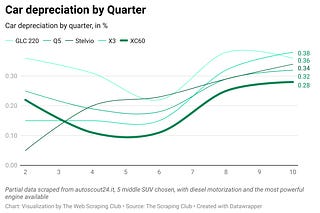
THE LAB #26: From internal API to insights.
Getting insights on the automotive industry by scraping a car resell website.
Sep 1, 2023 •
3
THE LAB #25: Bypassing Perimeterx in 2023
How to bypass PerimeterX anti-bot solution using both free and commercial solutions
Aug 17, 2023 •
4
THE LAB #24 - Bypassing Akamai using Proxidize
Scraping H&M website to collect e-commerce data, in a reliable way.
Aug 3, 2023 •
2
[
2
](https://substack.thewebscraping.club/p/bypassing-akamai-proxidize/comments)

Buy cheaper plane tickets using a VPN: truth or myth?
Debunking the myth of different ticket prices from different countries
Jul 20, 2023 •
[
2
](https://substack.thewebscraping.club/p/cheaper-plane-tickets-vpn/comments)

THE LAB #22 - Scraping Akamai protected websites
How Zalando and Rakuten use Akamai to protect its website and how to bypass this solution
Jul 6, 2023 •
THE LAB #21 - Bypass anti-bot challenges with AI
How Nimble Browser performs against the most famous anti-bot solutions
Jun 22, 2023 •
1

THE LAB #20 - AI powered web scrapers with Nimble Browser
How artificial intelligence makes web scraping easier
Jun 8, 2023 •

THE LAB #19: How to mask your device fingerprint
Beating the fingerprinting by Cloudflare is possible
May 26, 2023 •
THE LAB #18: How to scrape Reddit with Scrapy
Scraping subreddits without any commercial product, in two easy different ways.
May 11, 2023 •
1
THE LAB #17: Creating a dataset for investors - Tesla (TSLA)
The creation process for a dataset for stock market analysts: Tesla
Apr 28, 2023 •
3
[
2
](https://substack.thewebscraping.club/p/dataset-for-investors-tesla-tsla/comments)

THE LAB #16: How to scrape Datadome protected websites (early 2023 version)
Tools and techniques to scrape Datadome protected websites
Apr 14, 2023 •
1
THE LAB #15: Deep diving into Apify world
Let’s use the new python SDK to know better the Apify ecosystem
Mar 30, 2023 •
1

THE LAB #14: Scraping Cloudflare Protected Websites (early 2023 version)
How to scrape Cloudflare protected websites in 2023
Mar 16, 2023 •
[
2
](https://substack.thewebscraping.club/p/scraping-cloudflare-websites-2023-q1-update/comments)
THE LAB #13: Managing a fleet of scrapers with Scrapeops
Using Scrapeops dashboard to monitor your web scraping operations in large web scraping projects
Mar 2, 2023 •
1
THE LAB #12: Reverse-engineering Mobile API
A step by step guide with Charles Proxy and Android Emulator
Feb 16, 2023 •
4
THE LAB #11: The Anti-Detect Anti-Bot matrix
Feb 2, 2023 •
1

THE LAB #10: Bypass Cloudflare Bot Protection with GoLogin
A new way to scrape Cloudflare-protected website using antidetect browsers
Jan 19, 2023 •
3
[
3
](https://substack.thewebscraping.club/p/bypass-cloudflare-scraping-playwright/comments)

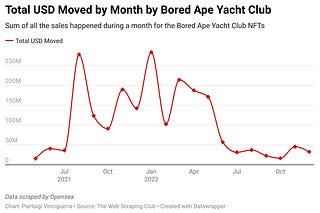
THE LAB #9: Scraping OpenSea NFT’s data
Getting winners and losers of the Bored Ape Yacht Club collection transactions
Jan 5, 2023 •
THE LAB #8: Using Bezier curves for human-like mouse movements
What are Bezier curves and why are important in web scraping?
Dec 9, 2022 •
1
[
1
](https://substack.thewebscraping.club/p/bezier-curves-web-scraping/comments)
THE LAB #7: Scraping PerimeterX protected websites
Is scraping Perimeterx website so difficult as it seems?
Nov 24, 2022 •
1
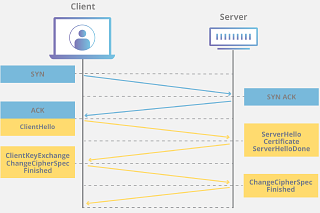
THE LAB #6: Changing Ciphers in Scrapy to avoid bans by TLS Fingerprinting
In other words: fake it until you scrape it
Nov 9, 2022 •
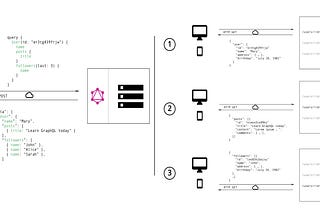
The Lab #5 - Scraping Airbnb.com using GraphQL
What is GraphQL and why it is used so widely
Oct 27, 2022 •
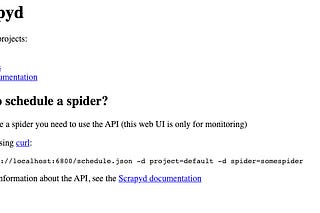
THE LAB #4: Scrapyd - how to manage and schedule a fleet of scrapers
Pro and cons of actual scheduling solutions for Scrapy
Oct 12, 2022 •
THE LAB #3: Scraping Cloudflare protected websites
Without buying any external software, for real.
Sep 27, 2022 •
8
THE LAB #2: scraping data from a website with Datadome and xsrf tokens
A real world use case of a simple scraper that does not get blocked by Datadome
Sep 16, 2022 •
7
THE LAB #1: Scraping data from an app
Sep 5, 2022 •
8
[
4
](https://substack.thewebscraping.club/p/the-lab-1-scraping-data-from-an-app/comments)