The Lab #5 - Scraping Airbnb.com using GraphQL
Excerpt
What is GraphQL and why it is used so widely
Here’s another post of “THE LAB”: in this series, we’ll cover real-world use cases, with code and an explanation of the methodology used.
Being a paying user gives:
-
Access to Paid Content, like the post series called “The LAB”, where we’ll go deep diving with code real-world cases (view here as an example).
-
Access to the GitHub repository with the code seen on ‘The LAB”
-
Access to private channels on our Discord server
But in case you want to read this newsletter for free, you will always get a post per week about:
-
News about web scraping
-
Anti-bot software and techniques insights
-
Interviews with key people in the industry
And you can always join the Web Scraping Club Discord server
Enough housekeeping, for now, let’s start.
Want to travel?
The travel industry has been one of the first to be impacted by digitalization. Booking.com, one of the largest websites for booking hotels around the globe, started its operations in 1997. Edreams.com, an air travel fares aggregator, went online in 2000. Airbnb is a fifteen years old online marketplace.
All these websites have in common an high traffic volume and a huge database of data points shown to their visitors. This means that every request made by the users should be responded to in the most efficient way, to save bandwidth and time. And it’s not just a case that these three websites have in common one thing: they all use GraphQL to retrieve data to the front end.
What is GraphQL
We can think of GraphQL as an API query language, with its own syntax and grammar. But it is also the runtime engine for interpreting this language and responding to these requests.
In other words, it’s a “query language,” that provides a consistent query layer for APIs, providing a single endpoint for developers to use when making requests.
This allows you to not only query the data but also control the structure of how each GraphQL API responds.
GraphQL was developed by Facebook in 2012 and later open-sourced in 2015.
Some more details
But how GraphQL helps websites to expose data more efficiently?
Modern websites have dozens if not hundreds of APIs exposing a single object, with all its attributes. With a single call made via GraphQL, you can gather data from the APIs needed, including only the requested fields in the output.
[

{kind=link}
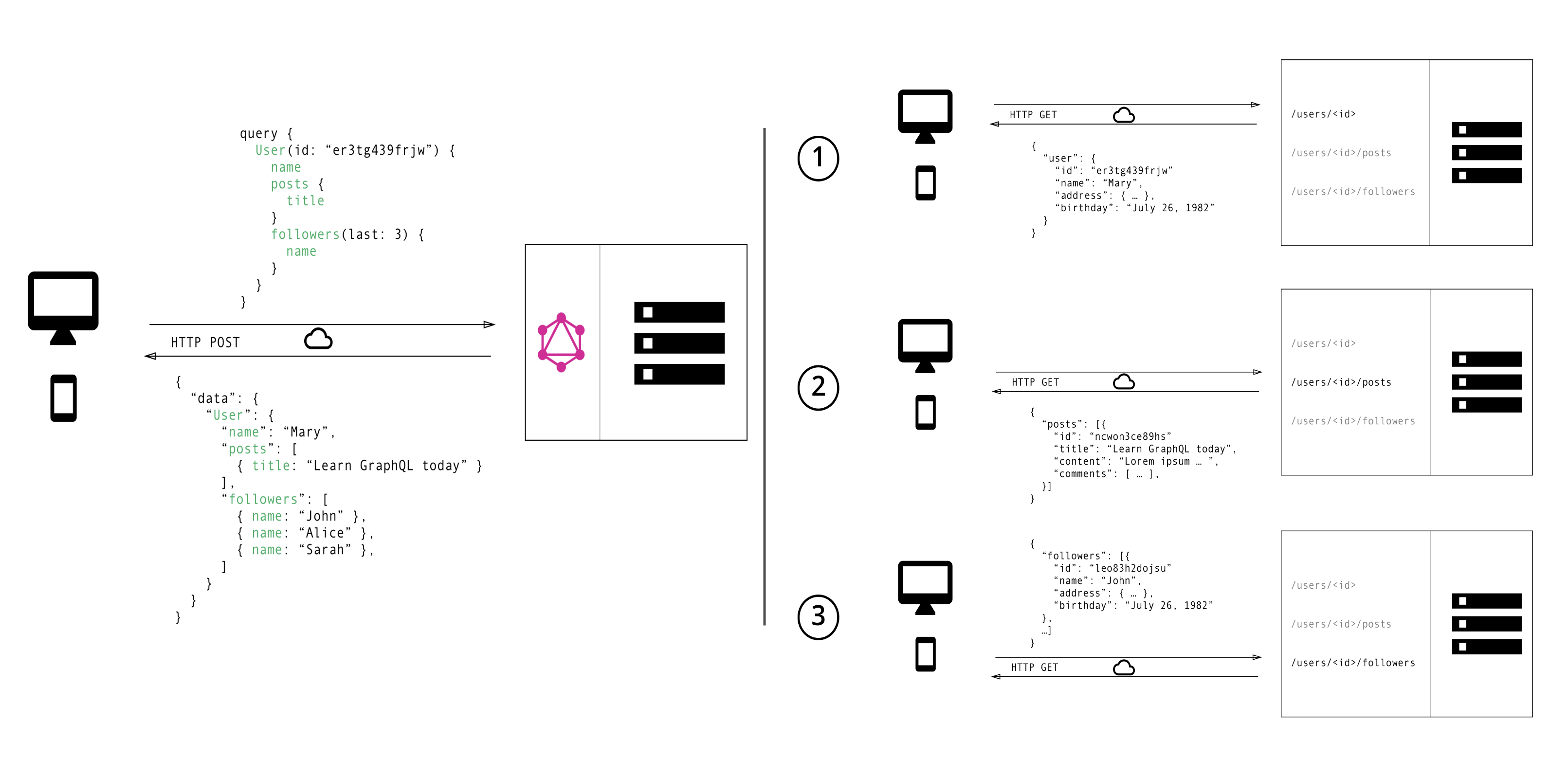
GraphQL at work
In this example from the Testproject’s blog that simulates the functioning of a blog, we have 3 different APIs on our website.
The first one lists the authors, with all their details: name, address, and birthday.
The second one is the list of the posts per author and their details: title, content, and comment list.
The last one lists the followers per author and their attributes: again name, address, and birthday.
Instead of calling the three APIs separately to get the data, and getting also unwanted fields, the user makes only one request to a single endpoint, specifying in the payload the fields he needs and the GraphQL engine will provide them.
This is possible because each object and the relationships between them are defined in its schema definition language.
For the ones of you that worked with relational databases, this operation is something pretty similar to designing the Database Entity-Relationship diagram. Mapping the entities in the GraphQL schemas allows its engine to understand where are all the information so that when it receives a request from a user, it knows which API to call to extract the fields needed to fulfill it.
The response is a JSON containing the result of the query, with the selected fields.
Web Scraping Implications
Because of its features, using GraphQL, when publicly available, to scrape a website is the preferred choice. We don’t overload the target websites with requests for HTML pages but instead, we get exactly the data we need in a JSON format, maintained by the website itself for its internal functioning.
Let’s see how Airbnb implemented it, simulating research for a place where to stay in Manhattan from 2022-11-10 to 2022-11-17, for two adults.
[

{kind=link}
Airbnb interface
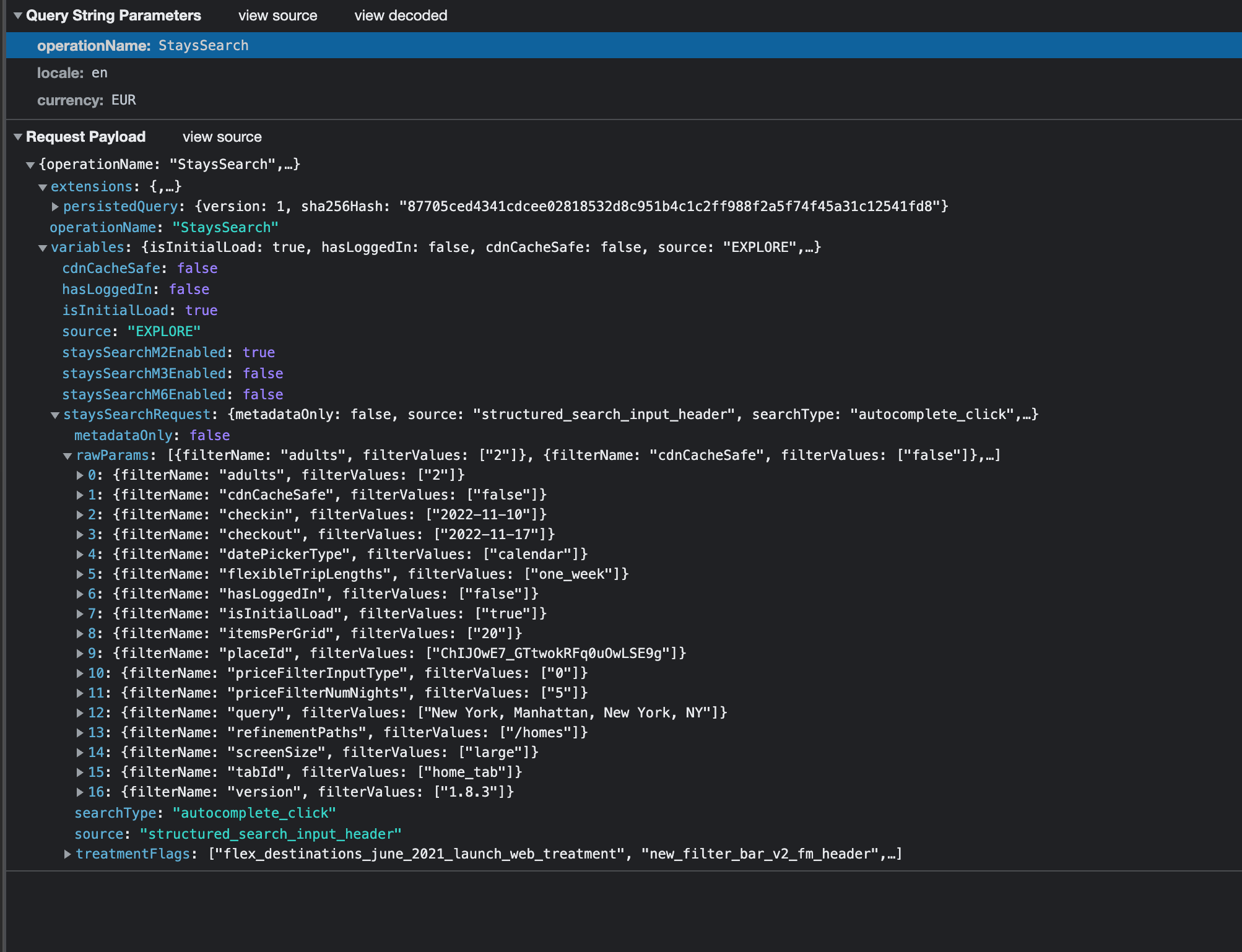
The payload sent to the GraphQL engine will look like the following.
[

{kind=link}
GraphQL Payload
You have surely noticed that in the rawParams list, we have the filters we’ve set in the search bar of the website, while the result contains all the data shown and much more.
[

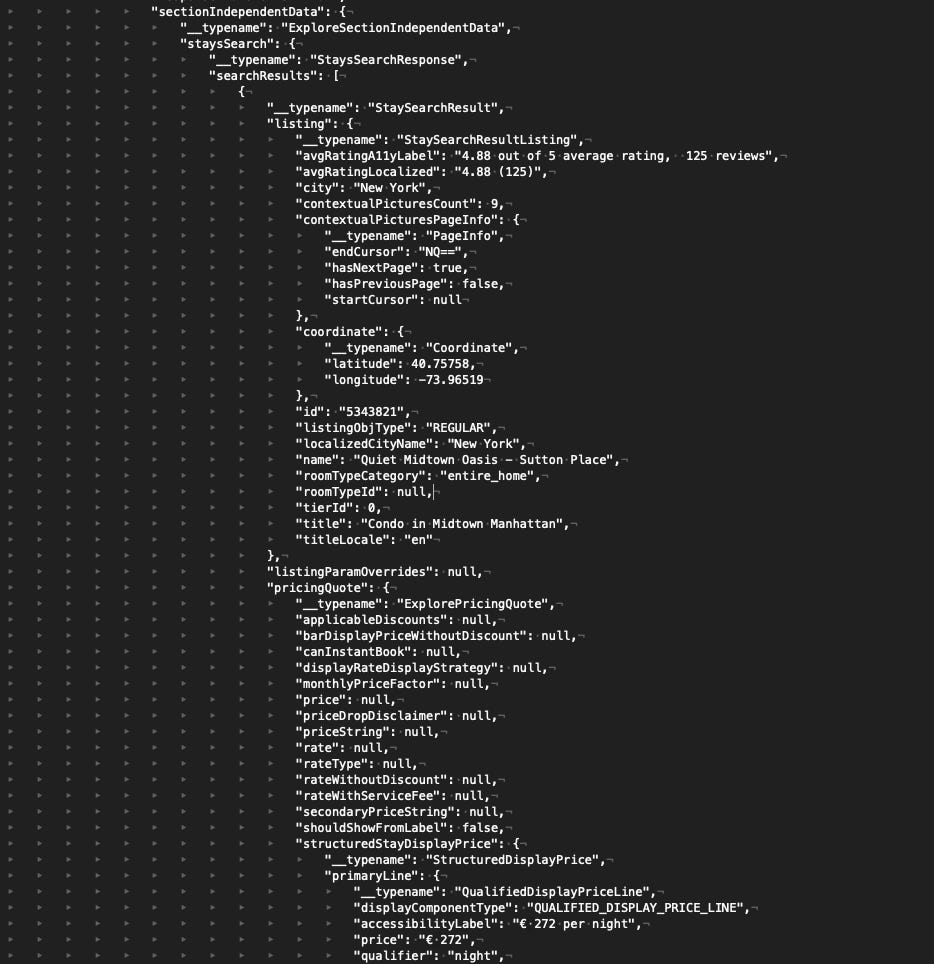{kind=link}
Airbnb API results
It seems we’re ready to implement our scraper for Airbnb.
It’s Scrapy time
The first thing is to create a Scrapy project and then define the data model for the output.
In the item file, we define the structure as follows :
from scrapy.item import Item, Field
import scrapy
class LocationItem(scrapy.Item):
location_id = scrapy.Field()
name = scrapy.Field()
title = scrapy.Field()
city = scrapy.Field()
url = scrapy.Field()
category = scrapy.Field()
currency = scrapy.Field()
pricepernight = scrapy.Field()
totalprice = scrapy.Field()
latitude = scrapy.Field()
longitude = scrapy.Field()
date = scrapy.Field()
arrival_date = scrapy.Field()
departure_date = scrapy.Field()
The next step is to reproduce the GraphQL call in Scrapy, starting from its Curl version copied from the network tab in the Developers Tools in Chrome (for readability reasons I’m not copying it here but I’ll post only the Scrapy code).
Let’s start by assigning to a variable the Headers needed in the request, stripping off what is not necessary to make it work. I’ve found out, as an example, that the request works perfectly without any cookies and some other fields.
API_HEADERS={
'authority':'www.airbnb.com',
'accept':'*/*',
'accept-language':'en-US,en;q=0.9',
'content-type':'application/json',
'device-memory':'8',
'dnt':'1',
'dpr':'2',
'ect':'4g',
'origin':'https://www.airbnb.com',
'sec-ch-ua':'"Google Chrome";v="107", "Chromium";v="107", "Not=A?Brand";v="24"',
'sec-ch-ua-mobile':'?0',
'sec-ch-ua-platform':'"macOS"',
'sec-fetch-dest':'empty',
'sec-fetch-mode':'cors',
'sec-fetch-site':'same-origin',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'viewport-width':'1083',
'x-airbnb-api-key':'d306zoyjsyarp7ifhu67rjxn52tv0t20',
'x-airbnb-graphql-platform':'web',
'x-airbnb-graphql-platform-client':'minimalist-niobe',
'x-airbnb-supports-airlock-v2':'true',
'x-csrf-without-token':'1',
'x-niobe-short-circuited':'true',
}
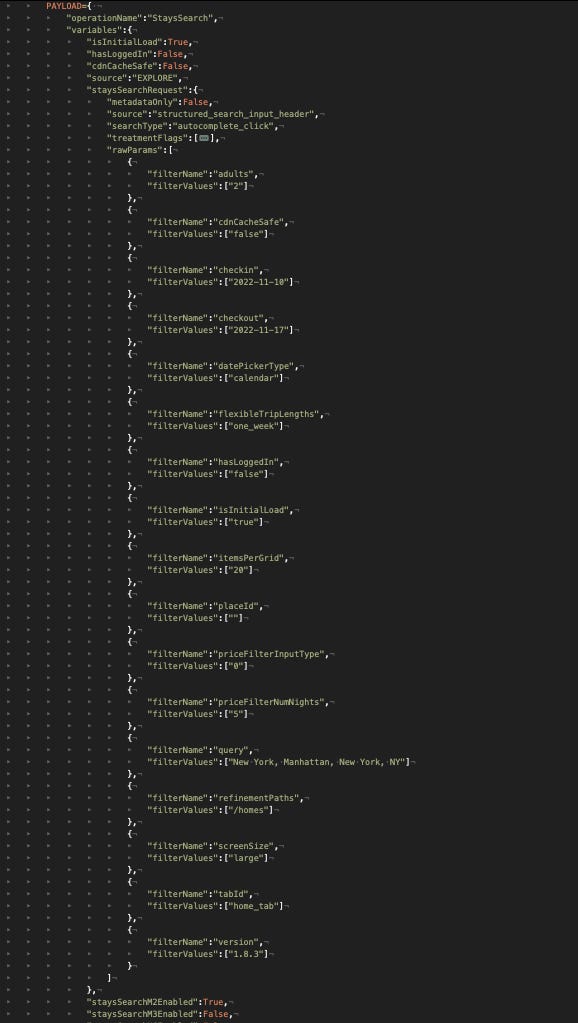
Let’s make the same for the Payload we need to send in the POST request, containing the GraphQL query (using an image for readability).
[

{kind=link}
Payload sent
In these first runs, we’ll keep the query filter fixed, just to test if the scraper works.
[

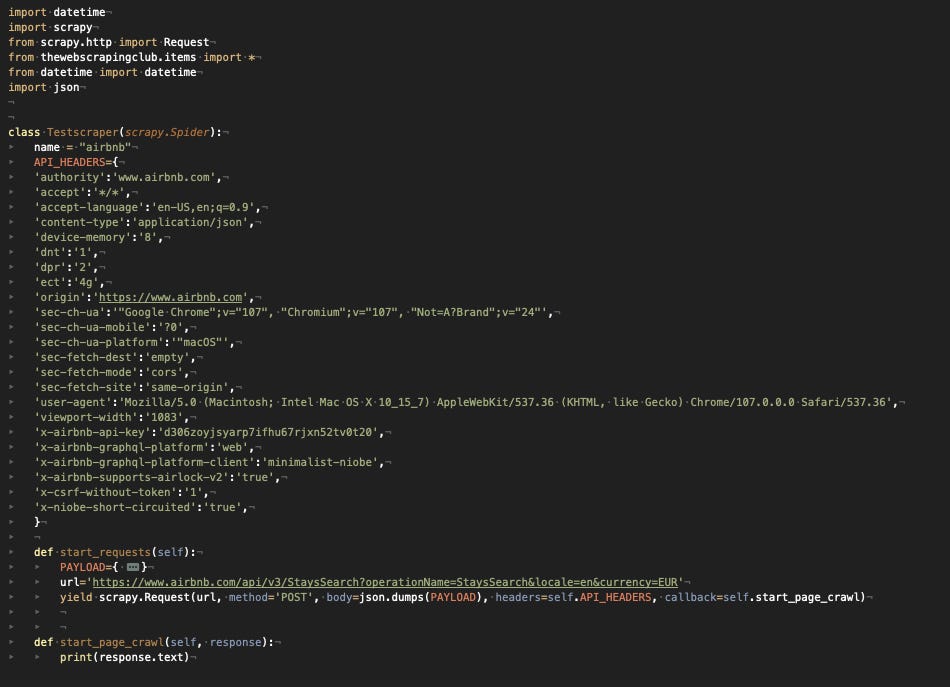{kind=link}
API headers
And we get the results!
[

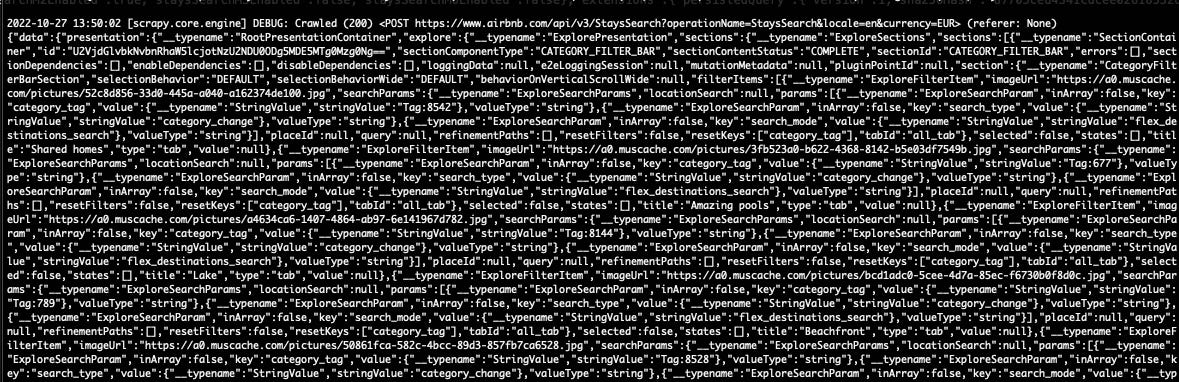{kind=link}
JSON results
Now it’s time to work on the JSON response parsing to have our items populated.
[
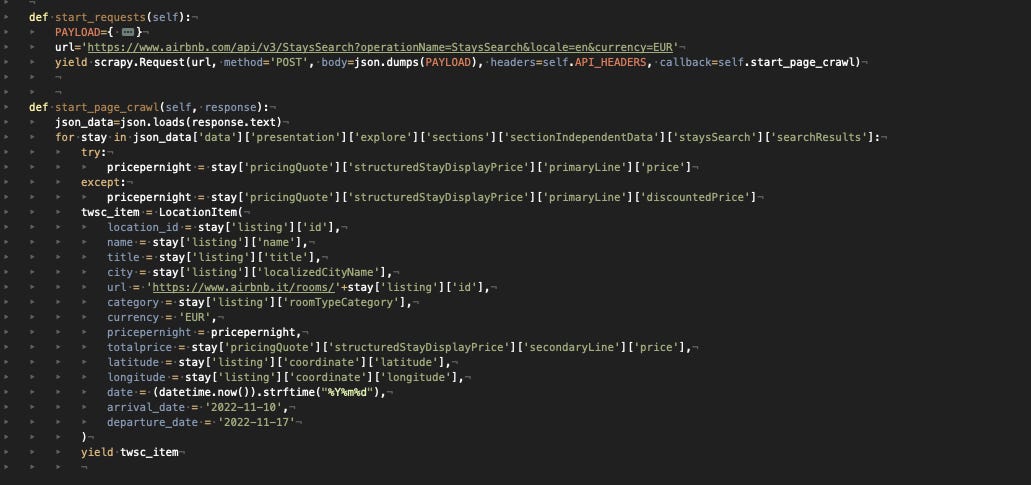
{kind=link}
JSON parsing
And here are the results
[

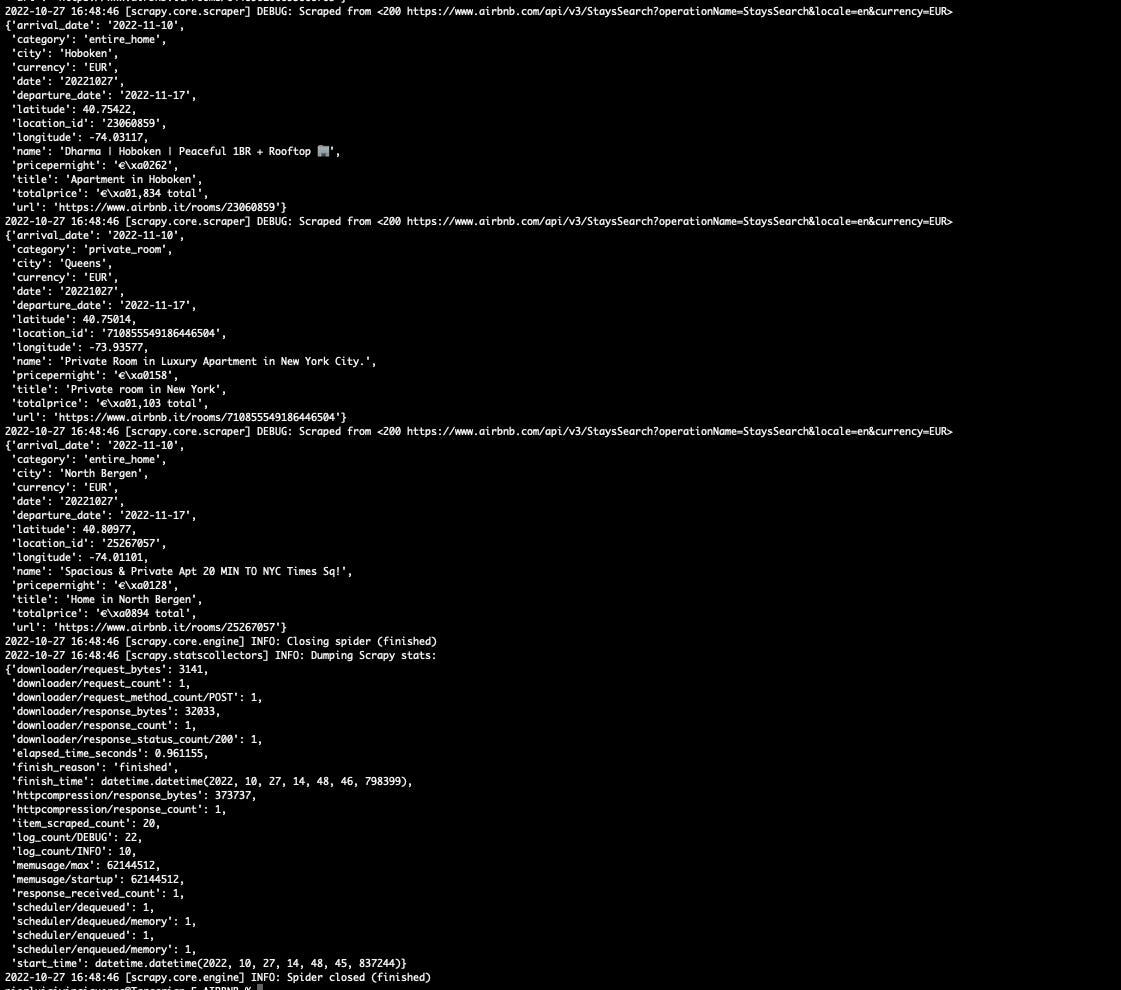{kind=link}
Scrapy results
Perfect! We’ve scraped the first 20 items, from the first page.
Let’s make it a bit more dynamic by using parameters at launch, so we can scrape different locations and dates.
With Scrapy we can pass user-defined arguments when starting a scraper with the following syntax:
scrapy crawl airbnb -a LOCATION="Roma, Italy" -a ARRIVAL_DATE="2022-12-20" -a DEPARTURE_DATE="2022-12-31" -a NIGHTS=10
Doing so, we can simply call these attributes in the scraper by writing
{
"filterName":"checkin",
"filterValues":[self.ARRIVAL_DATE]
},
{
"filterName":"checkout",
"filterValues":[self.DEPARTURE_DATE]
},
Modifying the PAYLOAD variable by adding all these variables, we’ve got a scraper that can get the data dynamically.
The Airbnb website lets you browse a maximum of 15 pages for a place, with 20 locations per page. So we’ll basically increment the offset in the payload by 20 for every iteration of the call up to 300.
It’s not the purpose of this post to make you scrape the whole city ads, but that’s something you could definitely do by studying a little more about how locations are shown on the map.
You can find the full code of the scraper on the Github repository of the Web Scraping Club, if you’re a paying user and don’t have access to it, please write me at pier@thewebscraping.club
Key Takeaways
We have seen at high level how GraphQL works. For more details there’s a ton of documentation available, this one is one of the best tutorials I’ve found.
We have also seen how to use GraphQL to pull data out of Airbnb website. It makes web scraping a lot easier, once understood the data model under the hood.
Thank you for reading so far, hope you’ve enjoyed this post.
Is any of our you working on something spectacular in web scraping and want to share with us? have you got any feedback about this newsletter? please write to pier@thewebscraping.club.