Using Cloud services for scraping it’s not a new thing: you can use virtual machines or containers deployed on the cloud and that’s something quite common nowadays.
I’ve also heard in the past people using AWS Lambda functions to do some scraping and was intrigued by the idea, so I’ve spent this week trying to understand how they can be used and the pros and the limits of this approach.
What is an AWS Lambda function?
AWS Lambda is a serverless computing service provided by Amazon Web Services (AWS) that allows developers to run code in response to events without the need to manage servers or runtime environments. This capability is particularly valuable for creating applications that need to respond quickly to new information or requests, without the cost of keeping a server running continuously.
Lambda functions are designed to execute code in response to specific triggers, which can originate from over 200 AWS services or direct HTTP requests via Amazon API Gateway. The triggers can include changes in data within an AWS S3 bucket, updates to a DynamoDB table, or custom events from application code or other AWS services. When triggered, Lambda functions execute the code to process the event, scaling automatically, both in frequency and in number of times the function is invoked.
Developers using Lambda can write functions in several programming languages such as Python, Node.js, Java, and C#. The environment is fully managed, meaning AWS handles the underlying compute resources, including server and operating system maintenance, capacity provisioning, automatic scaling, code monitoring, and logging. All that developers need to manage is the code itself and the associated configurations for triggering events.
Lambda functions are stateless, with no affinity to the underlying infrastructure, so they can quickly start, stop, and scale. AWS charges for Lambda on a pay-per-use basis, measuring compute cost through the function’s memory allocation and execution time, and this could be interesting for our web scraping purposes.
Deploying with Serverless
I had the idea for this post for some time but since I’m not a great expert with Lambda, I’ve always postponed it. Then I finally saw this repository, which has reduced the learning curve for deploying successfully a Lambda function with Selenium, so I decided to give it a try.
As far as I understand, we’re using Serverless, a service that helps us in deploying applications on AWS lambda using containers.
We’ll use a clone of the repository as a template and, after creating the image, we’ll upload it to Lambda.
In the Dockerfile we’re setting up the running environment, by installing all the missing packages and dependencies, while the code for the function we’re executing is contained in the main.py file.
All the code of the tests can be found in The Lab GitHub repository, available for paying users, under folder 48.SCRAPING-WITH-LAMBDA.
If you already subscribed but don’t have access to the repository, please write me at pier@thewebscraping.club since I need to add you manually.
Just to check if I understood correctly, I’ve made a small change to the main.py file and, instead of returning the example.com website’s HTML code, I’ve called an API to check my IP.
from selenium import webdriver
from tempfile import mkdtemp
from selenium.webdriver.common.by import By
def handler(event=None, context=None):
options = webdriver.ChromeOptions()
service = webdriver.ChromeService("/opt/chromedriver")
options.binary_location = '/opt/chrome/chrome'
options.add_argument("--headless=new")
options.add_argument('--no-sandbox')
options.add_argument("--disable-gpu")
options.add_argument("--window-size=1280x1696")
options.add_argument("--single-process")
options.add_argument("--disable-dev-shm-usage")
options.add_argument("--disable-dev-tools")
options.add_argument("--no-zygote")
options.add_argument(f"--user-data-dir={mkdtemp()}")
options.add_argument(f"--data-path={mkdtemp()}")
options.add_argument(f"--disk-cache-dir={mkdtemp()}")
options.add_argument("--remote-debugging-port=9222")
chrome = webdriver.Chrome(options=options, service=service)
chrome.get("https://api.ipify.org?format=json")
return chrome.find_element(by=By.XPATH, value="//html").text
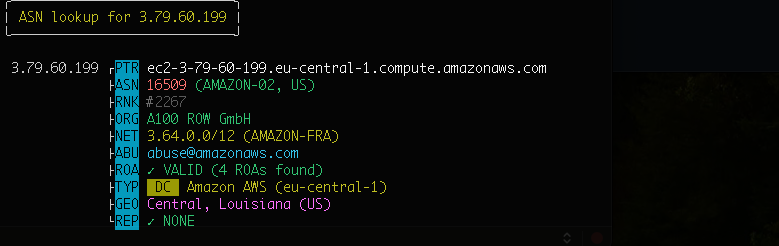
As you can imagine, the IP returned belongs to an AWS datacenter.
[

{kind=link}
In fact, if I analyze the IP returned with ASN, we can see it’s an IP from eu-central-1 (the AWS region I’ve set up), belonging to Amazon.
[
{kind=link}
By executing the function another time, I’ll get another IP from the same region.
With this little experiment, we can already understand some pros and cons of this solution.
We’re using AWS data center IPs, which are easily detectable and blocked by target websites since Amazon publicly discloses the range of IPs of their subnets. So, unless we’re masking them using a proxy service, we will not be able to scrape some websites.
On the other hand, since the IP is changing for every request, we’ve basically built an IP rotation system, at a fraction of the cost of the already cheap datacenter proxies.
Now that we’ve understood the basic concepts, let’s increase the difficulty: I want to pass a URL as a parameter to the function invocation and get the result from there.
Creating a Selenium Scraper on AWS Lambda
After our tests, what we want to achieve is that, given one URL in input, the function returns some fields in output, as a result of our scraping operations.
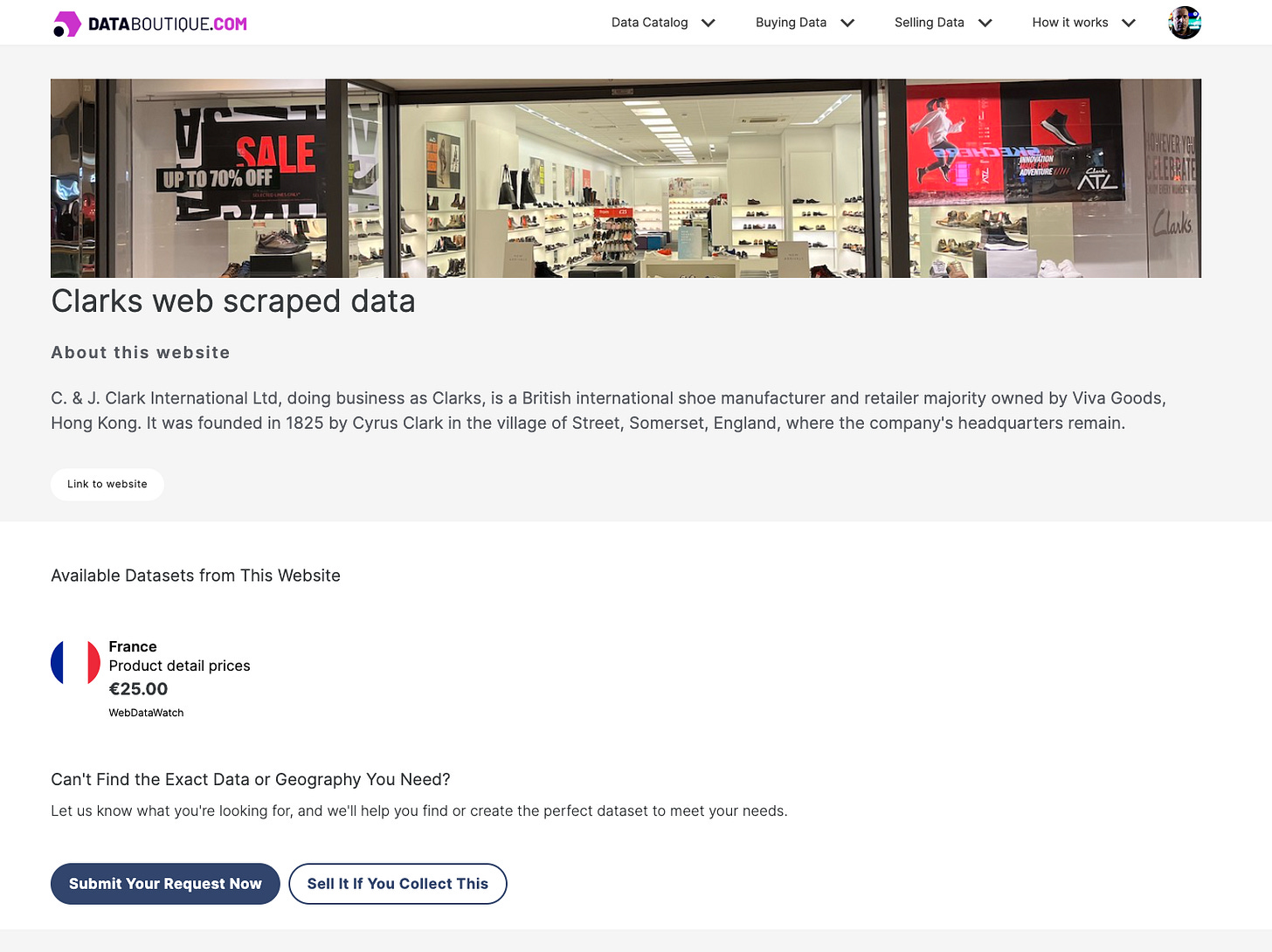
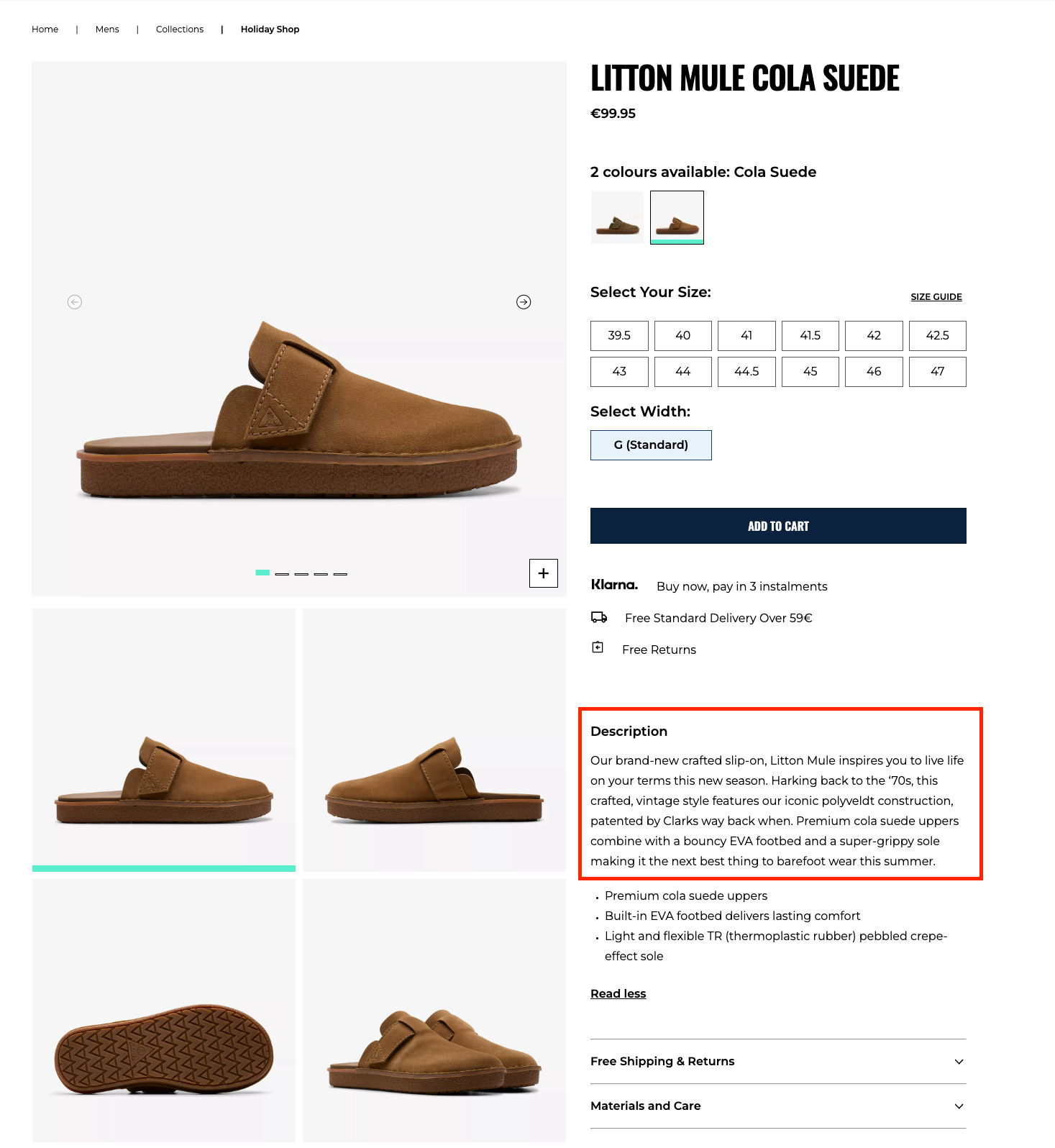
Let’s create a real-world use case: you just bought from Databoutique.com a dataset, let’s say Clark’s website, on its French version. It’s a standard price schema, with no extended product description, which is a field that we need.
[
{kind=link}
We can place a bid on the platform for the same website but with a different schema or we can scrape ourself the new field using the dataset as input.
Let’s follow this second path, by modifying the lambda function, so that we can pass two values in input: the product code and its URL, which we’re going to scrape to get the long description on the page.
[
{kind=link}
The new code will look like:
url = event.get('url', 'https://api.ipify.org?format=json')
product_code = event.get('product_code', 'n.a.')
This means that, when invoked, the URL parameter will be mapped to the URL variable and the same happens with the product_code. In case they’re missing, a default value is set.
The second phase is to scrape the data as a traditional Selenium scraper.
chrome = webdriver.Chrome(options=options, service=service)
chrome.get('https://api.ipify.org?format=json')
ip_address_str=chrome.find_element(by=By.XPATH, value="//html").text
ip_address_json=json.loads(ip_address_str)
ip=ip_address_json['ip']
chrome.get(url)
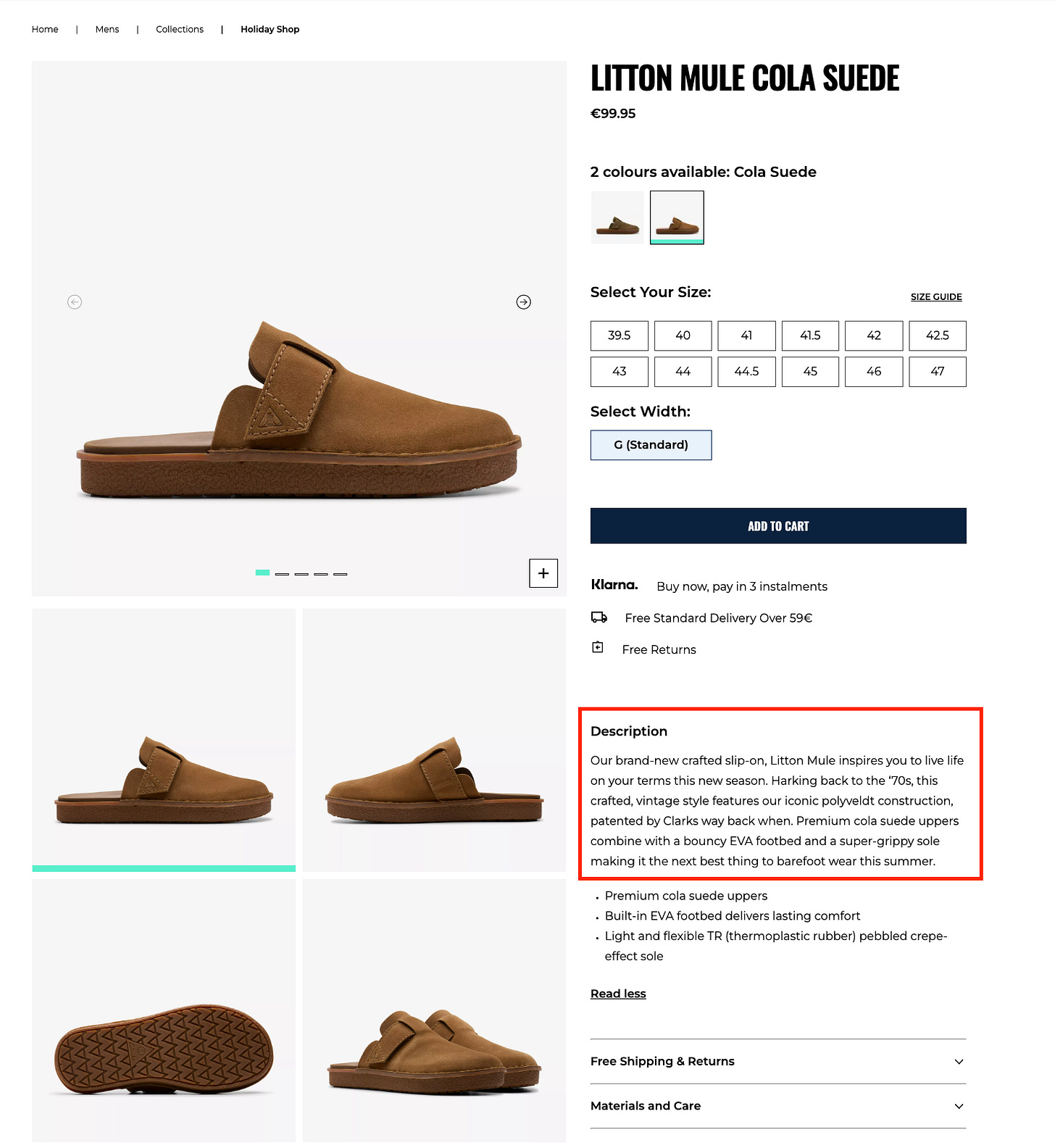
product_desc=chrome.find_element(by=By.XPATH, value="//p[@class='sc-afae01d3-3 fhQxiF']").text
I want to keep track of the IPs used, so I’m always making a call to the Ipify API to get it. After that, I load the specified page and get, via XPATH, the product description. A piece of cake.
[

{kind=link}
Last but not least, we need to return the data collected: in this case, I’ve decided to return a string with the fields separated by a ‘|’.
output_text=ip+'|'+product_code+'|'+product_desc
return output_text
After all these modifications to the main.py file, we can redeploy the function with the command sls deploy.
When the process ends, we can invoke again our function, but this time we need to add the new parameters:
sls invoke -f demo --data '{"url":"https://www.clarks.com/en-fr/litton-mule/26176574-p", "product_code": "26176574-p"}'
After a few seconds, the magic happens and we’re getting our results:
"18.199.105.169|26176574-p|Our brand-new crafted slip-on, Litton Mule inspires you to live life on your terms this new season. Harking back to the ‘70s, this crafted, vintage style features our iconic polyveldt construction, patented by Clarks way back when. Premium cola suede uppers combine with a bouncy EVA footbed and a super-grippy sole making it the next best thing to barefoot wear this summer."
Final remarks
I liked writing this article since it’s almost a new playing ground for me: while I’ve written several Lamba functions, mostly linked to generic APIs, it’s the first time I used it for scraping.
Is it a production-ready solution?
Yes, but it depends on our expectations. AWS Lambda has some limitations, the most important one is its maximum duration. If things haven’t changed recently, they can last up to 15 minutes, so it’s difficult to write a scraper for a full website.
The great part, instead, is that you have a fully scalable solution without the hassle of maintaining the hardware.
Let’s say you want to scrape the reviews from a certain product on Amazon, you can write a function that can be used for millions of products in a short time.
You can also write the function to write directly on your database or to text files sent to S3.
I think this approach is an extremely powerful way to do scraping on a narrow scope.