The Lab #35: Bypassing PerimeterX with Python and Playwright
Excerpt
Bypassing Perimeterx with free Python tools in 2023.
What is PerimeterX and how it work?
PerimeterX (now Human Scraping Defense) is one of the most famous anti-bot solutions available on the market.
It employs a sophisticated approach involving behavioral analysis and predictive detection, combined with various fingerprinting methods. These techniques assess multiple factors to distinguish between authentic users and automated bots attempting to access website resources.
The system’s defenses are powered by machine learning algorithms that scrutinize requests and predict potential bot activities. If any suspicious behavior is observed, PerimeterX might deploy challenges to verify if the source is a robot. In clear bot scenarios, it blocks the IP address from accessing site resources.
PerimeterX’s major defenses fall into four primary categories:
-
IP Monitoring: PerimeterX rigorously analyzes the IPs visiting a protected site. It examines past requests from the same IP, the frequency of these requests, and the intervals between them to spot bot-like patterns. The system also investigates the IP’s origin, whether it’s from an ISP or a data center, checks against known bot networks, and assesses the IP’s historical reputation, assigning a reputation score to determine its trustworthiness.
-
HTTP Headers: These headers in HTTP requests and responses reveal important details about the request. PerimeterX uses this data to identify bot-like activities, scrutinizing whether the headers are unique to specific browsers or default ones used by HTTP libraries. Inconsistencies or missing headers often lead to denial of access, as legitimate browsers usually send consistent and complete header information.
-
Fingerprinting: This complex defense layer includes several techniques:
-
Browser Fingerprinting: Gathers details about the browser, its version, settings like screen resolution, operating system, installed plugins, and more to create a unique user fingerprint.
-
HTTP/2 Fingerprinting: Provides additional request details, similar to HTTP headers, but with more comprehensive information like stream dependencies and flow control signals.
-
TLS Fingerprinting: Analyzes the initial, unencrypted information shared during the TLS handshake, such as device details and TLS version, to identify unusual request parameters.
-
-
CAPTCHAs and Behavioral Analysis: PerimeterX uses its own CAPTCHA, ‘HUMAN Challenge’, to differentiate between humans and bots. It monitors webpage interactions, like mouse movements and keystroke speeds, to detect non-human behavior. This is highly effective as replicating the complexity of genuine user interactions is difficult for bots.
[

{kind=link}
Despite its robust defenses, we still can use some techniques and tools to bypass them and scrape data from target websites.
All the techniques and tools we see in this article are for testing purposes and should not be used to harm any website or its business. Please use web scraping techniques in a ethical way. If you’ve got any doubt about your web scraping operations, please ask for legal advice.
Analyze the target website
The target website for this test is Neiman Marcus, a well-known department store that also has an e-commerce website, from where we’ll try to scrape product prices.
[

{kind=link}
We immediately see from Wappalyzer that it’s protected by PerimeterX, so we’ll not consider a standard Scrapy strategy.
About the scraping strategy, instead, let’s try to load a product category page and see what happens.
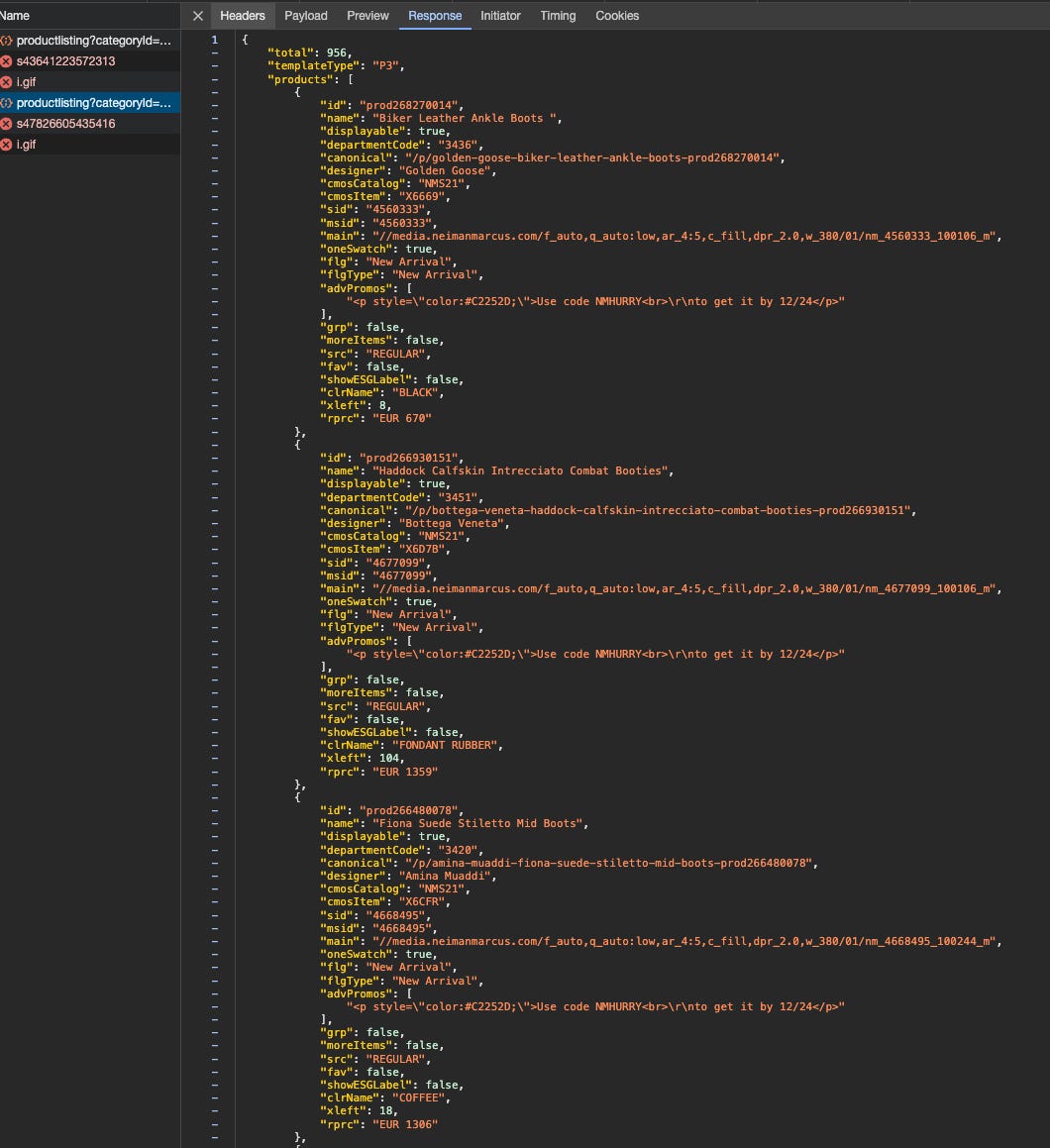
When opening this Women’s Boots catalog, we notice that the first page loads and has the product data in the HTML and also inside a JSON. If we go to page two, the website makes a call to an API endpoint, with all the data we need.
[

{kind=link}
We can load the following URL in our browser to get the same results
https://www.neimanmarcus.com/c/dt/api/productlisting?categoryId=cat45140734&page=2&currency=EUR&countryCode=IT
This means that all we need is this categoryID and then we can happily crawl the website, gathering data from its API endpoint, saving bandwidth and with a low request number.
First solution: hRequests ✅
In our previous The LAB article where we tested the hRequests package, we have already seen that it could be a solution.
In the GitHub repository available for the paying readers of the newsletter you will find the full code of the Scrapy spider that uses hRequests to get all the prices from a product category.
But lately, after a Python package upgrade on my machine, something has broken and cannot work anymore with all the features of hRequests, but still the scraper partially works for the whole Women Clothing category (22k items approx). In fact, without using any proxy, I could gather about 5k items before receiving a Human Captcha, when running from a local environment.
Let’s try adding a rotating residential proxy service and some error handling: whenever we get a captcha, we’ll close the hrequests session and then open a new one, which will load the first page of the product category.
By doing so, we’re resetting the session, clearing the cookies previously collected, and getting new ones. In fact, changing the IP is not enough if we don’t get rid of the cookies saying we didn’t pass the challenge.
Second solution: Playwright + Brave ✅
Let’s use the lessons learned from the previous solution and write a second one, this time using Playwright and Brave Browser.
In this case, we’re loading the home page with a Brave Browser session with a persistent context, so we can store the cookies on the disk.
browser = p.chromium.launch_persistent_context(user_data_dir='./userdata'+str(retry)+'/',channel='chrome',executable_path='/Applications/Brave Browser.app/Contents/MacOS/Brave Browser', headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"],proxy=proxy)
This seems something that makes the difference for PerimeterX, since if I’m not saving them, I’ve got more errors during the execution.
From the code, you’ll notice that I’m using a dynamic name for the folder used by the context. This is because I want to use a different folder every time I get “caught” by the CAPTCHA and need to restart the scraper from 0. Even if I close the browser, since I’m using a persistent context, every cookie and browser file will be stored in that directory, and opening a new browser session using the same directory for the context will throw a CAPTCHA again. Surprisingly, at least for me, even if I clear all the cookies before closing the browser with the context.clear_cookies() command, this is not enough: we need a brand new context folder.
The variable CHROMIUM_ARGS instead is set as the following:
CHROMIUM_ARGS= [
'--no-sandbox',
'--disable-setuid-sandbox',
'--no-first-run',
'--disable-blink-features=AutomationControlled'
]
We’re disabling the sandbox (honestly I think it’s a legacy from Selenium scrapers who needed these options, but if it works, don’t touch it) and disabling the first run screen on the browser, together with the bar that says that the browser is controlled by automation.
Last but not least, I added the slow_mo option in case we need to launch it from a server, which is more performant than a PC.
The logic of the scraper is the same as the previous one, we’re loading the first pages of the browser and then using the internal API endpoint.
You can check the code on our GitHub repository available for the paying readers of the newsletter, in case you’re a paying subscriber and don’t have access to it, please write me at pier@thewebscraping.club since I have to add you manually.
Final considerations on bypassing Perimeterx
If we need to bypass PerimeterX anti-bot solution for our scraper, we have different tools and tricks we can use. A recurring pattern I’ve seen writing this article is that we cannot directly point at the internal API but we need to follow a legit path to our final purpose.
Another pattern I’ve seen is that the block is IP independent: whenever your browser session has been flagged as malicious, changing the IP is not enough but you need a brand new identity with a new and clean browser session and a new IP.
In any case, we need a browser to pass the first challenges and not get blocked and a good network of residential IPs.
Of the two solutions, probably the first with hRequests is less compute-intensive so it’s the preferable one, but it seems to me that the dependencies of this package make it unstable on some configurations, like my Mac. After my latest update, the scripts I wrote some weeks ago are no longer working, and needed to rewrite them.
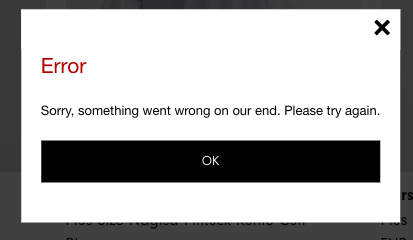
The irony is that when creating these two scrapers, I found an issue on the website itself. Both the scraper went to error when trying to load page 84 of the Women Clothing category: I’ve struggled for some hours to figure out what was happening and then, trying to load the page on the browser, here’s the result.
[
{kind=link}
See you next Sunday with an article about the super APIs, full of promotional codes for you.