THE LAB #7: Scraping PerimeterX protected websites
Excerpt
Is scraping Perimeterx website so difficult as it seems?
Here’s another post of “THE LAB”: in this series, we’ll cover real-world use cases, with code and an explanation of the methodology used.
Thank you for reading The Web Scraping Club. This post is public so feel free to share it.
Being a paying user gives:
-
Access to Paid Content, like the post series called “The LAB”, where we’ll go deep diving with code real-world cases (view here an example).
-
Access to the GitHub repository with the code seen on ‘The LAB”
-
Access to private channels on our Discord server
But in case you want to read this newsletter for free, you will always get a post per week about:
-
News about web scraping
-
Anti-bot software and techniques insights
-
Interviews with key people in the industry
And you can always join the Web Scraping Club Discord server
Enough housekeeping, for now, let’s start.
What is PerimeterX?
PerimeterX is one of the most well-known anti-bot solutions, used by some of the top-tier websites on the net. They recently merged with Human Security, another company in the anti-bot industry but more focused on fraud prevention and account abuse.
How to detect PerimeterX anti-bot solution?
If we analyze the tech stack of the target website with Wappalyzer, PerimeterX appears in the security section with a good degree of precision. Detecting it by inspecting the network tab in the developer tools is pretty easy. When active, you will see that PerimeterX sets a cookie with the following format when loading the first page of the website.
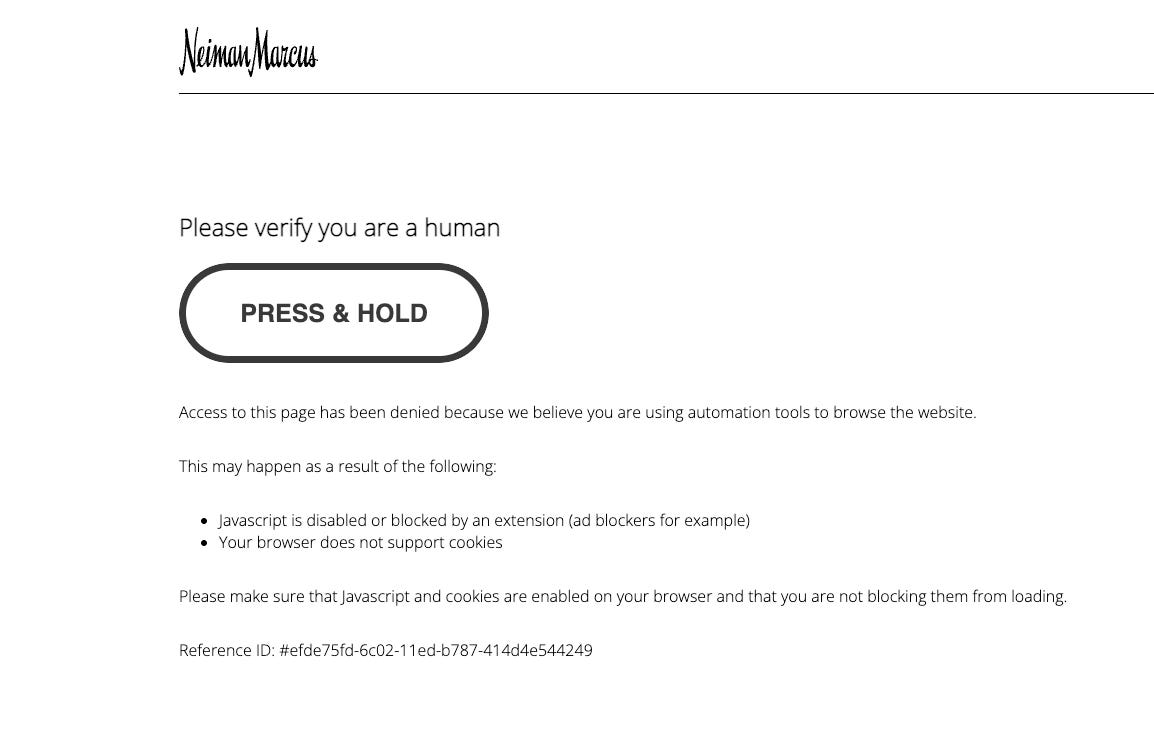
The Human Challenge
The Human Challenge is the PerimeterX “trademark” when talking about anti-bot challenges. Instead of throwing a Captcha or a Re-Captcha, their anti-bot solution shows this big button that a human must keep “pressed” with the mouse until the challenge is solved.
[

{kind=link}
PerimeterX Human Challenge
In a 2020 interview published on the company website, Gad Bornstein, product manager at that time before going to Meta, explained that this peculiar solution has several advantages both for website users and owners.
It’s 5x faster for humans to solve compared to other solutions and this leads 10-15x lower abandonment rate with Human Challenge compared to reCAPTCHA,
Another interesting topic in this interview is how the solution works:
Bot Defender also works in real time, so every time a user gets a new page, we calculate their behavior, path, fingerprints and all those machine learning models. Then we get a score that defines whether you’re a human or a bot.
And if you are categorized as a bot, the Challenge triggers. This means that scrapers need to pretend to be like humans but also act like humans.
Real-world examples
Finding a test website for this article has not been easy, the websites I knew were using PerimeterX now paired it with also Cloudflare bot management which would have affected our tests.
We’ll use neimanmarcus.com as a target website but before starting coding, I’m sharing with you this good article about PerimeterX made by Zenrows. It lets you understand in detail how it works and it describes a hypothetical solution for reverse engineering its functioning.
In my opinion, despite being very interesting for understanding what happens under the hood, I would not implement this kind of solution in my scrapers. The algorithm can change often and this requires restarting the reverse engineering process. The most durable method is instead trying to simulate being a real user, using as less resources as possible.
Coding
Following this principle, let’s start coding using a simple Scrapy project.
Let’s study the website and see if there’s any API showing the products. I choose to browse the women’s clothing section and go to page 2:
[

{kind=link}
Neiman Marcus API
Bingo! We’ve found the following API, returning the product catalog:
This means that given the product category id, we can have all the information needed for our scraper in the response.
Let’s try then to scrape all the Women’s Clothing category with a simple Scrapy spider that you can find as usual on our GitHub repository of The Lab (if you can’t see it, write me at pier@thewebscraping.club for getting access, it’s for paying readers only).
I’m skipping the JSON parsing explanation since it’s quite straightforward and out of topic here.
[

{kind=link}
Surprisingly, it works quite well even if I didn’t set any default request headers but only slowed down the request rate from the default options.
I get some 424 errors while crawling, after a random amount of pages. It seems to me that PerimeterX is doing its job so I will try to avoid these errors by adding proper request headers.
Things get better but still cannot reach the end of the category. But I’ve noticed it’s not a matter of an IP ban because if I try from my browser to reach the latest URL, I could do it without problems. And If I start again the scraper, it works
I tried to handle the 424 error, in order to request again the URL in case of errors but with mixed results, we still don’t reach the end of the catalog, even if we can browse more than 40 pages.
In this case, we have 2 options:
-
split the execution into much smaller chunks, each distributed to a different machine
-
go headful and see if things improve
Inside a cost-savvy production environment, I would go for the first. Headful browsing is much more expensive than executing smaller VM machines dedicated to headless browsing.
But now we can see if the execution results improve when done headful.
The Playwright way
I’ve coded the same scraping logic on a base scraper made with Playwright, the only change I’ve made is that now we can call the category id of the category we’d like to scrape as a parameter of the python program.
I’ve implemented two functions, one that moves the mouse randomly inside the page (move_random_mouse) and the other one that scrolls down a bit the page simulating the mouse wheel (scroll_down). They are both far from perfect, especially the first one, which I’d like to rewrite using the Bezier curves principles but for the moment they’re making their job.
It seems that this solution triggers PerimeterX much less often, but sometimes we still got the Human Challenge as a response.
The latest addition to the scraper is then a loop for when we trigger it, so we cool down the environment and then restart asking the pages, and this little naif trick made us complete the scraping of the whole category. Again the full code is available on our GitHub repository of The Lab.
Key takeaways
Today we have seen how to scrape a PerimeterX-protected website and with some plain vanilla solutions, we made it without any particular effort. Probably our target website had the Anti Bot solution configured with some lower entry barriers, to avoid triggering for real users and some other websites won’t be so easy to scrape.
PerimeterX is in any case a great solution, widely adopted and chosen by some of the top websites around, like Fiverr or Crunchbase.
The Lab - premium content with real-world cases
-
THE LAB #6: Changing Ciphers in Scrapy to avoid bans by TLS Fingerprinting
-
THE LAB #4: Scrapyd - how to manage and schedule a fleet of scrapers
-
THE LAB #2: scraping data from a website with Datadome and xsrf tokens
If you liked this post, please share it with your friends and colleagues and spread the word about The Web Scraping Club