THE LAB #4: Scrapyd - how to manage and schedule a fleet of scrapers
Excerpt
Pro and cons of actual scheduling solutions for Scrapy
Here’s another post of “THE LAB”: in this series, we’ll cover real-world use cases, with code and an explanation of the methodology used.
In the future, this kind of content will be available only to paying subscribers. Being one of the first of the series, this one will be available for free until the 19th of Oct 2022, then will be behind a paywall.
Being a paying user gives:
-
Access to Paid Content, like the post series called “The LAB”, where we’ll go deep diving with code real-world cases (view here as an example).
-
Access to the GitHub repository with the code seen on ‘The LAB”
-
Access to private channels on our Discord server
But in case you want to read this newsletter for free, you will always get a post per week about:
-
News about web scraping
-
Anti-bot software and techniques insights
-
Interviews with key people in the industry
And you can always join the Web Scraping Club Discord server
Enough housekeeping, for now, let’s start.
Web scraping is like eating cherries: one website pulls the other and you will soon find yourself with hundreds of sparse scrapers in your servers, scheduled via crontab randomly.
In this post, we’ll see how to handle this complexity with some tools that use the Scrapy embedded functions to create a web dashboard for monitoring and scheduling your scrapers.
Why Scrapy?
It’s much easier to manage the Scrapy spiders because they have already bundled inside a telnet connection and a console that allows external software to query the scraper status and report it in the web dashboards.
From the Telnet console, you can basically start, pause and stop scrapers and monitor statistics about the Scrapy engine and the data collection.
All you need to do is to log in via telnet to the address of the machine where Scrapy is running, using the username and password provided in the settings file.
These are the default values in setting.py file when a scraper is created:
TELNETCONSOLE_ENABLED = 1
TELNETCONSOLE_PORT = [6023, 6073]
TELNETCONSOLE_HOST = '127.0.0.1'
TELNETCONSOLE_USERNAME = 'scrapy'
TELNETCONSOLE_PASSWORD = None
In case the password is not set, Scrapy will automatically generate a random one at the beginning on the execution of the scraper. You should see during the start up a line like the following:
[scrapy.extensions.telnet] INFO: Telnet Password: fe53708491f51304
Once you connect to the console, you can retrieve your scraper stats with the command
stats.get_stats()
and get the stats you usually get at the end of the execution
{'log_count/INFO': 10,
'start_time': datetime.datetime(2022, 10, 11, 18, 19, 8, 178404), 'memusage/startup': 56901632,
'memusage/max': 56901632,
'scheduler/enqueued/memory': 43,
'scheduler/enqueued': 43,
'scheduler/dequeued/memory': 13,
'scheduler/dequeued': 13,
'downloader/request_count': 14,
'downloader/request_method_count/GET': 14,
'downloader/request_bytes': 11016,
'robotstxt/request_count': 1,
'downloader/response_count': 9,
'downloader/response_status_count/404': 2,
'downloader/response_bytes': 30301,
'httpcompression/response_bytes': 199875, 'httpcompression/response_count': 9,
'log_count/DEBUG': 14,
'response_received_count': 9,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/404': 1, 'downloader/response_status_count/200': 7,
'request_depth_max': 2,
'item_scraped_count': 5,
'httperror/response_ignored_count': 1, 'httperror/response_ignored_status_count/404': 1}
or the status of the Scrapy engine and control its execution by pausing or terminating it, using the following commands:
engine.pause()
engine.unpause()
engine.stop()
Now we have understood how to gather stats and command the scraper from remote, we could certainly create some scripts to gather all these pieces of information, but there’s no need to reinvent the wheel, as there are already several open-source solutions that can help us.
Scrapyd
Scrapyd is an application that schedules and monitors Scrapy spiders, with also a (very) basic web interface. It can be used also as a versioning tool for the scrapers since it allows creation of multiple versions for the same scraper, even if only the latest one can be launched.
Let’s configure together a basic scrapyd server.
Starting from an Ubuntu machine we install the scrapyd python package
sudo pip install scrapyd
To make its web interface visible from the outside, we also need to change the file /usr/local/lib/pythonX.Y/dist-packages/scrapyd/default_scrapyd.conf (location may vary according to your python installation path and version), setting the bind-address option to 0.0.0.0.
bind_address = 0.0.0.0
In case we want to access the service also with a username and password we need to set them in the proper variable.
username =
password =
Let’s save the new values and start the server with the command
sudo scrapyd
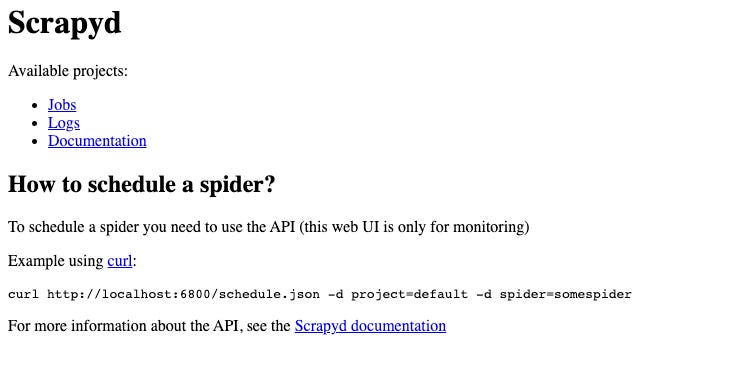
To check if the server is up and running and reachable from the outside, just connect using your browser to the IP address of the server and the port 6800 (the default one).
You should get a website page like the following.
[

{kind=link}
Scrapyd server at work
If not, check if the Scrapyd process is up and running and the firewall rules on the server.
We’ll use the address we’ve just put in the browser also for deploying and scheduling our scrapers. Let’s use a scraper we’ve already built, the “bookstoscrape” project we created in a previous post.
Scrapy provides an easy way to deploy scrapers with Scrapyd, straight from the scrapy.cfg file.
In the machine where there’s the scraper code, let’s add in the scrapy.cfg file the deploy target server.
[deploy:scrapyd]
url = http://18.184.49.196:6800
project = bookstoscrape
We gave to our scheduling server a name (scrapyd) and for this server, the current project will be called “bookstoscrape”.
On the same machine we install also the scrapyd and scrapyd-client python package:
pip install scrapyd scrapyd-client
and finally we can add our bookstoscrape project to our monitoring server.
scrapyd-deploy scrapyd -p bookstoscrape
We should get a message like that everything is ok
[

{kind=link}
Scrapyd scraper deployed
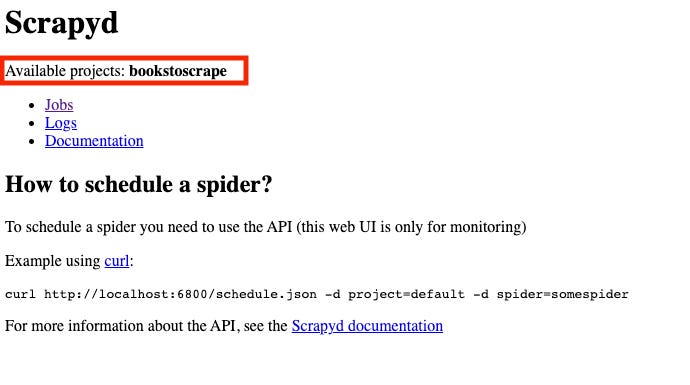
and on the server our project “bookstoscrape” should appear between the available ones.
[

{kind=link}
Scrapyd scraper deployed as seen on the web
Now let’s try to run our scraper and see what happens on the server.
Instead of using the standard “scrapy crawl booksscraper” command, we’ll call the schedule.json endpoint of our scrapyd server.
[

{kind=link}
Scrapyd schedule execution
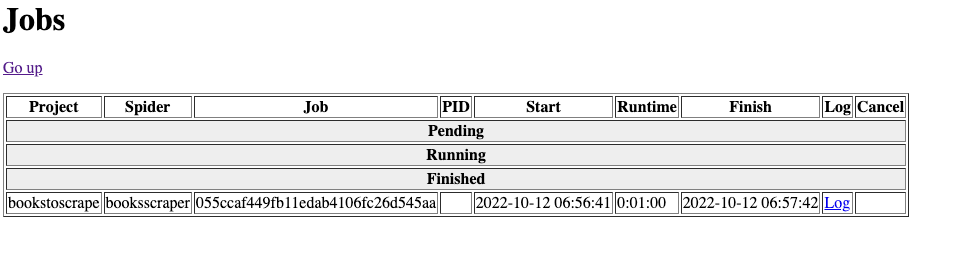
A job on the scrapyd server started, it called on the server machine the deployed version of the scraper and on the web interface we can see live its execution.
[

{kind=link}
Scrapyd job table
Hurray! We have our scraper log accessible in real time!
Pro and cons
The main advantage of this solution is that we can centralize all the scrapers’ execution in one place, where we can monitor them and read their logs.
But there are also a lot of downsides to this centralized environment:
-
All the executions, starting from the Scrapyd server, have the same IP, so a proxy solution is needed for the IP rotation
-
The web interface is very basic and things get messy when adding many scrapers
-
There’s no way to have the scheduling plan on a user interface, since you need to schedule the API calls from crontab.
A better UI and scheduler
There are several open-source tools for improving Ui and scheduling, as you can see from a quick search on GitHub but some of them are not updated for a long time and others are very minimal and buggy.
I’ve recently discovered Scrapeops and its free tier seems to be something worth trying.
Disclaimer: I’m not actually a customer of Scrapeops and I’m not having any partnership with them, and I’m not getting paid for this article.
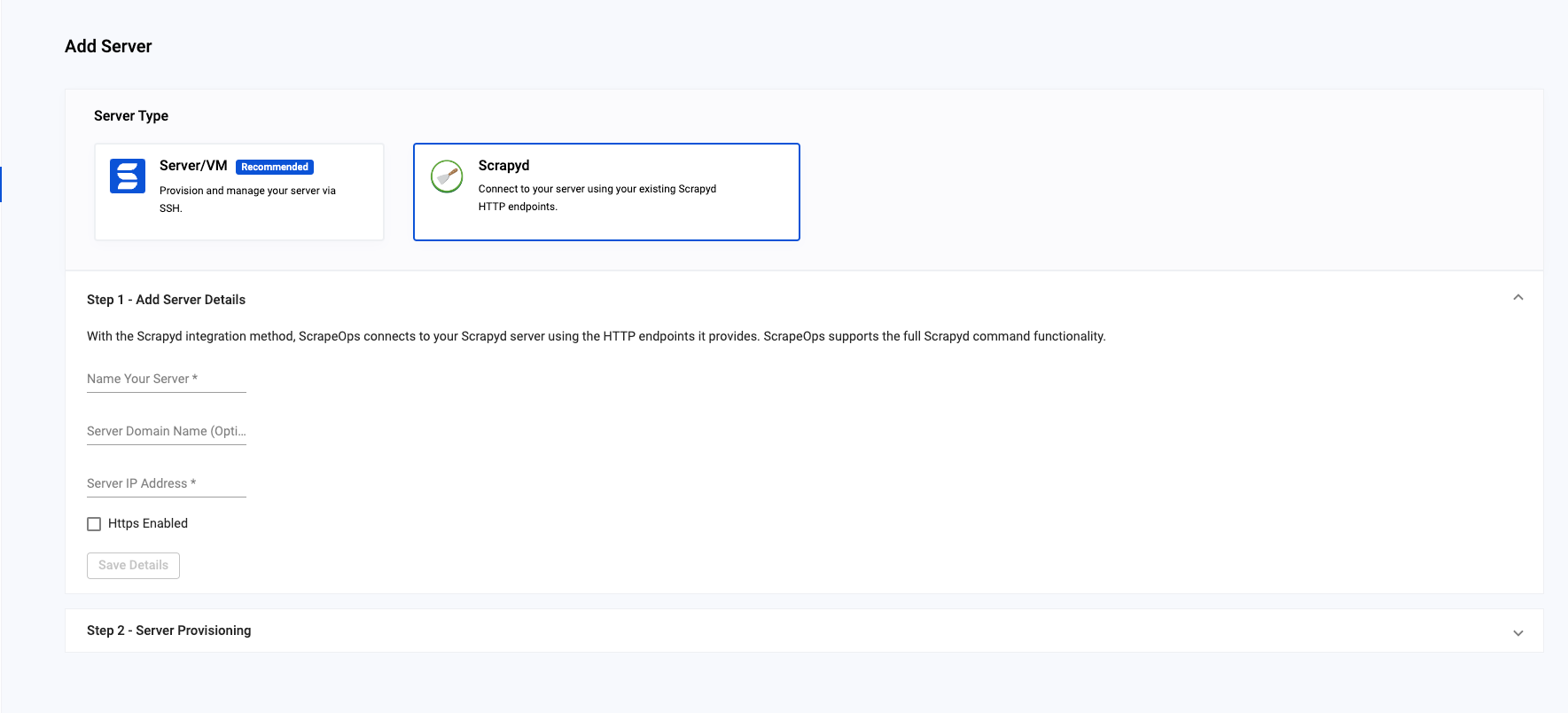
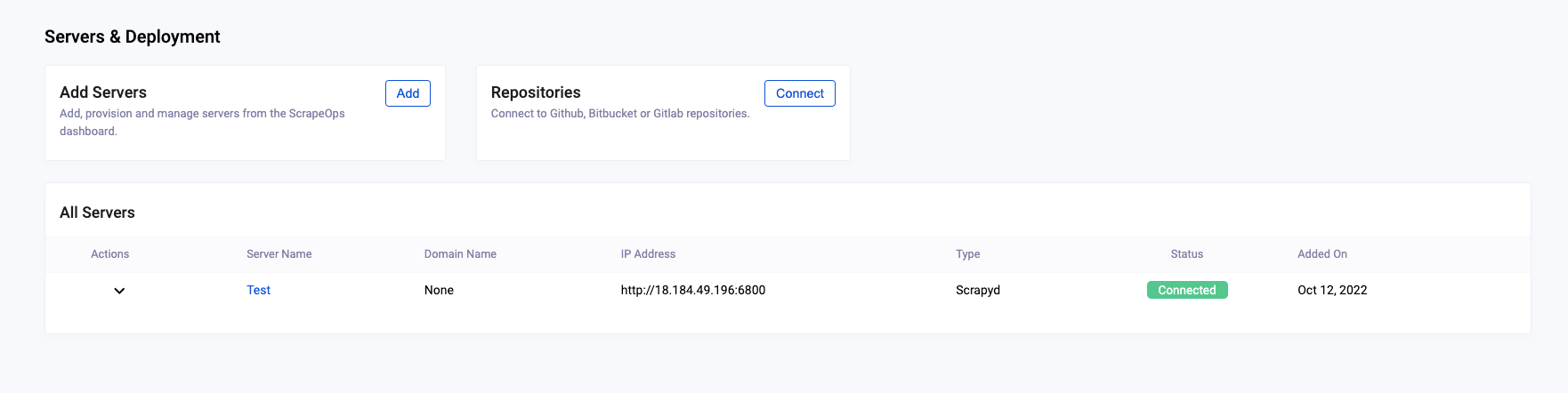
With some easy steps, you can add your Scrapyd server to your account from the web interface.
[

{kind=link}
Scrapeops servers managing
Then you need to link your server to the Scrapeops scheduler, following these instructions, and modify the scraper settings.py file of the scraper.
[

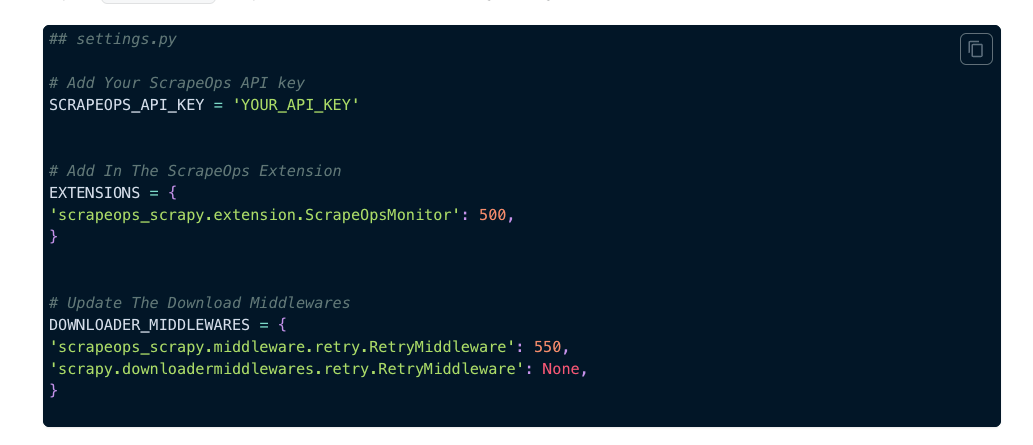{kind=link}
Scrapeops Scrapy config
After doing so, you will see the list of your connected servers and can schedule your scrapers’ execution as you like. Of course, more servers it means you have more starting IPs for your executions but, structurally, if you need a great number of IPS, you have to think how to distribute your loads to a great list of proxies.
[

{kind=link}
Scrapeops server list
A scraper execution will look like the following
[

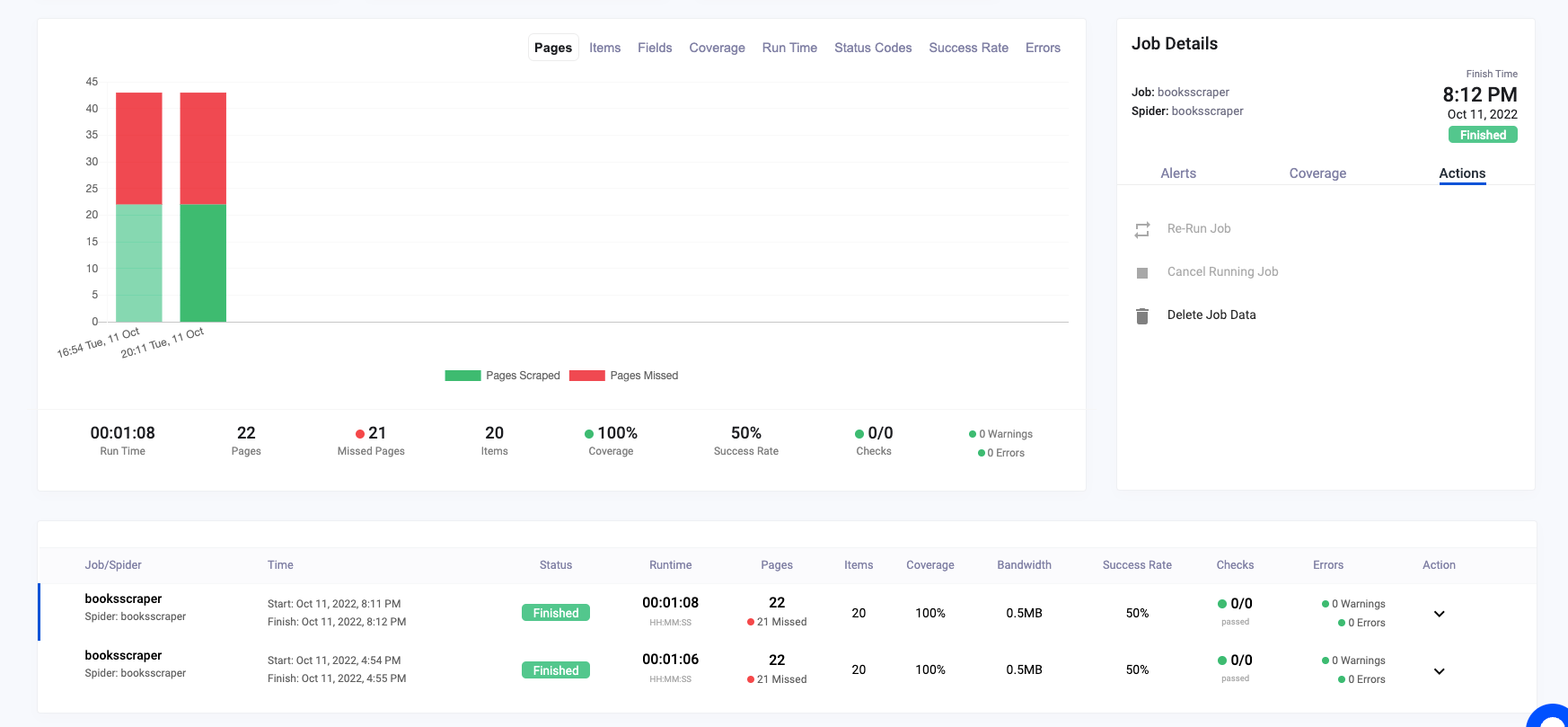{kind=link}
Scrapeops jobs monitoring
Another great feature is the possibility to add servers where there’s no Scrapyd installed or with scrapers not created with Scrapy, but I didn’t try this feature yet, like also the proxy aggregation tool could be very interesting for teams who use several providers.
Final remarks
-
Managing a great number of scrapers is a great challenge in itself
-
Scrapyd is a tool that helps monitor their executions live and read their logs, but it’s too basic as a stand-alone solution.
-
There are several solutions that, on top of Scrapyd, improve its usability and features but I still don’t see the must-have product to handle a fleet of hundreds or thousands of scrapers with several technologies, preserving the flexibility needed to operate.
-
Scrapeops seems a good solution for medium-sized projects with some interesting features like proxy optimization and multi-server architecture.
We’re done with this ‘The Lab” post, hope you enjoyed it even if we didn’t see a specific solution but a more generic problem.
As usual, any feedback is welcome at pier@thewebscraping.club, feel free to share this post with anyone who might be interested.
Thank you for reading The Web Scraping Club. This post is public so feel free to share it.