THE LAB #30: How to bypass Akamai protected website when nothing else works
Excerpt
And without paying any commercial solution. An ode to trivial solutions.
In the past weeks, I’ve had some headaches with some Akamai-protected websites: our running scrapers stopped working, very few items were collected before getting blocked, and there seemed to be no way to fix them.
In this post, we’ll see the process that brought me to the final solution, which is not the best, but it works without using any commercial tool.
Understanding the context
The target website is a fashion retailer, well-known in the industry, with around 40k items available. Until some weeks ago, every product was scraped by a Scrapy spider run, using concurrent executions, one per product category. The website was already protected by Akamai, but splitting the execution from one scraper for the whole website to different executions allowed us to obtain the whole product catalog before getting blocked.
But some weeks ago, I think an update on the Akamai anti-bot solution happened since not only me but also other people in our Discord server faced the same issue: the scrapers were immediately blocked at the first request on the target website.
Nothing new in the life of a professional web scraper, but let’s use this case to detail a bit more the process of fixing a scraper, independently from the issue.
The first step to take is to know what challenge you’re facing and, as usual, this step is solved by the Wappalyzer Browser Extension, which shows the actual anti-bot situation.
[

{kind=link}
In this case, we have reCAPTCHA in combination with Akamai. I honestly don’t remember if it was installed before this issue but the fact that other people are complaining about Akamai these days makes me think that it has been updated recently.
The debugging process
What I usually do, and I’m not saying it’s the best debugging process, is try to discard easy-to-detect issues and causes. In this case, we’ve got a Scrapy spider running on a virtual machine in a datacenter, so the first thing is to understand if running it on a local environment solves the situation.
If we’re able to scrape some items by running it on a laptop, then we understand it’s not a scraper spider but an IP issue and take the subsequent actions, like changing the cloud provider where the machine runs or adding a proxy, in case datacenter IPs are banned.
Unfortunately, that was not the situation: also running the scraper locally, it didn’t work, so we needed to rework it.
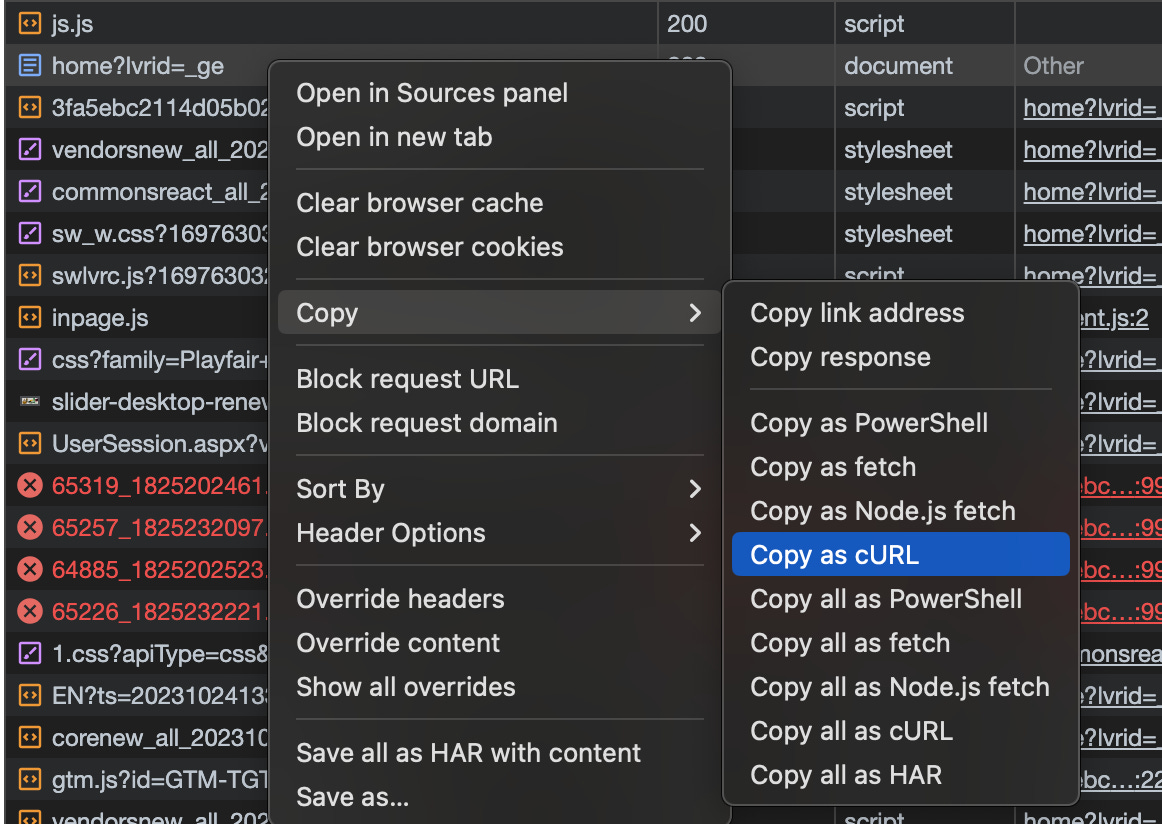
Another thing easy to detect is the need for a headful browser: if we could get the full HTML code by replicating the browser request on the website by using cUrl, for sure we’re not gonna need a headful browser.
How to test it it’s really simple: by opening the browser’s developer tools, you can copy the exact cUrl request corresponding to the browser call.
[
{kind=link}
In this case, we’re lucky enough to see that we could get the full HTML, so we don’t need a headful browser, so we understood that we should rewrite the Scrapy spider without using Playwright or another headless browser.
From now on, it’s only a matter of trial and error. Recently I’ve had much luck with scrapy_impersonate and its way of masking the JA3 TLS fingerprint, I decided to use it as the first possible solution, but it didn’t work.
I’ve got some connection errors to the API endpoint used by the Scrapy spider, so probably the anti-bot protection was doing its job properly.
Since the only way we could get data actually is by using a cUrl request, I’d like to understand if this still works if we don’t pass the cookies we got from the browser. This is because I usually prefer cookies to be generated during the runtime since it’s a common behavior, rather than then that could be stale and no longer valid and generate errors.
But in this case, the behavior is the opposite: without cookies, the request didn’t work, reducing the number of cookies to the only ones relatable to Akamai instead, it does.
We’re starting to figure out a plausible solution, we only need to get that cookie when the scraper starts.
Filling up the cookie jar
The main issue here is that we cannot load any single page of the target website without getting blocked, so we cannot get the cookies needed to keep scraping it.
Even if we know it’s not needed to get data, I’ve also tried to load the API using Playwright, so maybe the needed cookies could be generated, but I’ve been blocked with a captcha every time.
So it seems we’re a bit stuck at this point: since the website has also a mobile app, what if we try to scrape data directly from there, using the procedure described in the first episode of The Lab, ?
Scraping data from an app - is it viable in this case?
I’ve opened Fiddle Everywhere and set up the connection, putting it in the middle between my iPhone and my router. In this way, I could track the calls made by the app to the target website, trying to figure out if there’s a simpler way to get data.
In fact, API endpoints dedicated to mobile traffic are usually less protected by anti-bots, to avoid the waste of traffic and resources on phones to solve particular challenges.
This is quite true also for our target website: while this is the cUrl call from the website,
curl 'https://www.luisaviaroma.com/en-us/sw/home?lvrid=_ge' \
-H 'authority: www.luisaviaroma.com' \
-H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8' \
-H 'accept-language: en-US,en;q=0.8' \
-H 'cache-control: no-cache' \
-H 'cookie: PIM-SESSION-ID=mLaLD8yo5I4NrLxi; _abck=46F48CEB95E3D51CC9B83AD53C9D2C23~-1~YAAQPbATAmZGf2mLAQAA+WFrbgqqQgkuwgHqU4yDriN58tKRg0CXzZOcYgyBxJ47qvzZCP0vGTiNz2CQ7k0dY9189CmvzJMaDLdbwwj1y1naP/8pvFo0AEAD1OLdLUB3Yp/Zw/AjCURzQ1cjjVNDbgLW1DeL2jGQvrBCPV8vr7epbx+Z4RZ1J3g3mlSyBL0kqea5SaiNurJl4OwMJikB6Qd936wehFnDHm1cqzPIJL8VrGMGkulbx7Xv2DfGZk+Q1O0+ID1KGjpqjL90xcx4jIxcj4UxWybIk2EoQTTKSNkOXlJtqCHOHkACSaHcx0x40joVpGDNckuGfXyHThXsRROltYzdkNoNIIIquWJIX31PVJoYgR5qcCJ1Y6hQj+G51zwsspxE4b4RJHNZ0skql48P5yotw0efFIhYEeEUDeIsXA0=~-1~-1~-1; ak_bmsc=582223EFC292AA8C048EB1D101AE0BB1~000000000000000000000000000000~YAAQPbATAmdGf2mLAQAA+WFrbhWcV+/RWrV8qjI5esXPBPUzu4fsT1YqNiStIv3+jeHTn051t1661U8tsIXVR7idDEnbX7AkIOazMXI8ZCl/6yLkIuTSD01yxqpGKlDnuOCTHI9E659p5FapdEuIqxRLe/Yec1rGUr6Tr90GSKt0kkyThVzSWm3j413emLU8EXvdOtE6tBf3HiVxg2MIg407MHfsrSiHX7RU8wg10DKRsYJixEwu1ZTbwJzII9N9EUeK5QXsHd+8bcw95KT2YpFK8YATUsgrmL1M9d/nPccX86W7EtCjgroP1ci6PomaFb/npUP6ZETVcBnsW2X+fdf57Digxz/M9w/mHDcHGcrdewJ7+WgB9rOHSL/PmYCc8rzK16oAHYrSaaIaEDV1nnc=; bm_sz=762B5079CAA3EFD37C2B2C1FB1A1E0E8~YAAQPbATAmhGf2mLAQAA+WFrbhVaCJtV/2Aed2xGinD4y32Rw5YTGiWgAWkNI8Pvxv/N4dcW/UVebZOF4Rjb6v8hO7z4cHCACWLf3CilMAu2rmWMzxqzTljksoVW04mkQwqfzf/Zy3KOEsLMx1rTQWf9pbAC3VhayUvcScTRVtJtmsMtRdPqyEDLkybORglq+EJDh3y7vZ8YNJqnzwHowig781pcVFOE8WoBxJHlLXPDaG93+3myLFP0UYiF0dEDMua0DTwUkrRUmcmV4j9V4+z64tnJgN8UtXgnbNPHMzoGorVi4eCTVhPQcMqr1IGi76K3JLtW4D/UUUTj5F386a8+~3556664~3485745; lnb=eyJhbGciOiJkaXIiLCJlbmMiOiJBMTI4Q0JDLUhTMjU2In0..PbOTdYC5rAVNvzoYYxIPzg.zHy-cKWmp_AjIp8EENbnWS_ArZAtA7aAEEfYantqLXdYb5-xxP8rkmDQls2AkaH2EQI-1xw6tq18TukhXTl06BjyYCPaPl7VNPfK0mZ4CGmMEmuh_2t2-zH_rRygb9WPzoyFHxNpGPsYZxXdB8pKcCy_Bl0CsvZSfrlACDz6V7w.zrJvleUCjCePu-kcwIsKXA; lna=eyJhbGciOiJkaXIiLCJlbmMiOiJBMTI4Q0JDLUhTMjU2In0..lrCftqctSh87ojv3q8rAyA.RXfRhs_qOQu8GuYQqJssBJxGLwrUq9-taE7u_zC6YaRD2QaME4ykG3CQA5CqODxNVvRxhyIZadUwh_kwffLGCY9JpnVTrIODCfyLjmbyaSoOlHaEwk3R15sY2bF5A87_ZbYHEKgIYcOTouTuMRD0-5BIq2f_QC6yeiJetf7ivtm0N4x0YeNIZ7Yr7VqBQbvPNpEonOiXS3orK0B6JaUBHH2TcDA5hxv-WgDiOrAum8b2g2FjTEvvGsjjohvzILQnCCsTpDjtSo0kLV2YfRLybZeOgD35jO2kpgaYvSfqDkLieA9s3f11LXtn2DUtz97H.hNWJV44Lp33_61BHLkh2iw; bm_sv=942DB838B9ABA64485A8469ED54B9342~YAAQPbATAtxGf2mLAQAAeaxrbhX/x8iDU5vgQveKZSXDMORGGvRt8mExqaj7S1N5s1Hahq2shLs9hIYY4JH6PNoErhnUJDM4gvqCoXDKf1jP1oLwvBj1vHIZwr8XyeEN9Dn/yt9lUyZzxM/J/sr0nmZHp6ZFWhU6cpuS4ngl1+ocw/LuxwIQ8YUrqO8xVtenqZGYb0odhTvsAwpfOPNbK5MC9+k40X7FcQzNLa2p8Tm2i4UGCS6qeYQKnKWy+/T/iW0Yn8Ky~1' \
-H 'pragma: no-cache' \
-H 'referer: https://www.luisaviaroma.com/en-us/sw/home?lvrid=_ge' \
-H 'sec-ch-ua: "Chromium";v="118", "Brave";v="118", "Not=A?Brand";v="99"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "macOS"' \
-H 'sec-fetch-dest: document' \
-H 'sec-fetch-mode: navigate' \
-H 'sec-fetch-site: same-origin' \
-H 'sec-fetch-user: ?1' \
-H 'sec-gpc: 1' \
-H 'upgrade-insecure-requests: 1' \
-H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36' \
--compressed
a more simplified version of the API call for product listing from the app is
curl -H "host: api.luisaviaroma.com"
-H "accept: application/json, text/plain, */*"
-H "env: PROD"
-H "__lvr_mobile_api_token__: st=1698364568~exp=1698366668~acl=*~hmac=016b3004ee65e46577d73d334f97bd239a85c74b8993c0b82e2341f906c8cdc7"
-H "user-agent: LVR/2.1.130 (iPhone; iOS 16.6.1)" -H "accept-language: it-IT,it;q=0.9"
-H "accept-encoding: gzip, deflate, br"
"https://api.luisaviaroma.com/lvrapprk/public/v1/catalog/widgetcatalogbyskus?PlainSkus=77I335001-MjUz0,78I335014-MTA40,78I335008-MjA10,77I335004-MTAw0,77I0N6010-QkxBQ0s1,78I50R033-MDA20,78IVKF019-QkxBQ0s1,77IXY0017-QkxBQ0s1,77IYQ0012-UElOSw2,77IGD2074-MDEw0,78IY5H019-OTAwMA2,77I1KT050-MTk5OTE1&Language=IT&Country=IT&CurrencyView=EUR&CurrencyFatt=EUR&App=true&format=json"
A much simpler call, but with a big elephant in the room:
-H "__lvr_mobile_api_token__: st=1698364568~exp=1698366668~acl=*~hmac=016b3004ee65e46577d73d334f97bd239a85c74b8993c0b82e2341f906c8cdc7"
An HMAC (Hash-based message authentication code) is a string set of data that helps authenticate the client with the server, to avoid third parties like us using API designed for the App. Since these tokens change around every 20 minutes, probably they are created by using the expiration timestamp and a secret key embedded in the app. They get then concatenated and hashed, maybe with other info, and the token is created.
So, unless we reverse engineer the token creation process, we’re at the same point as before.
Final solution
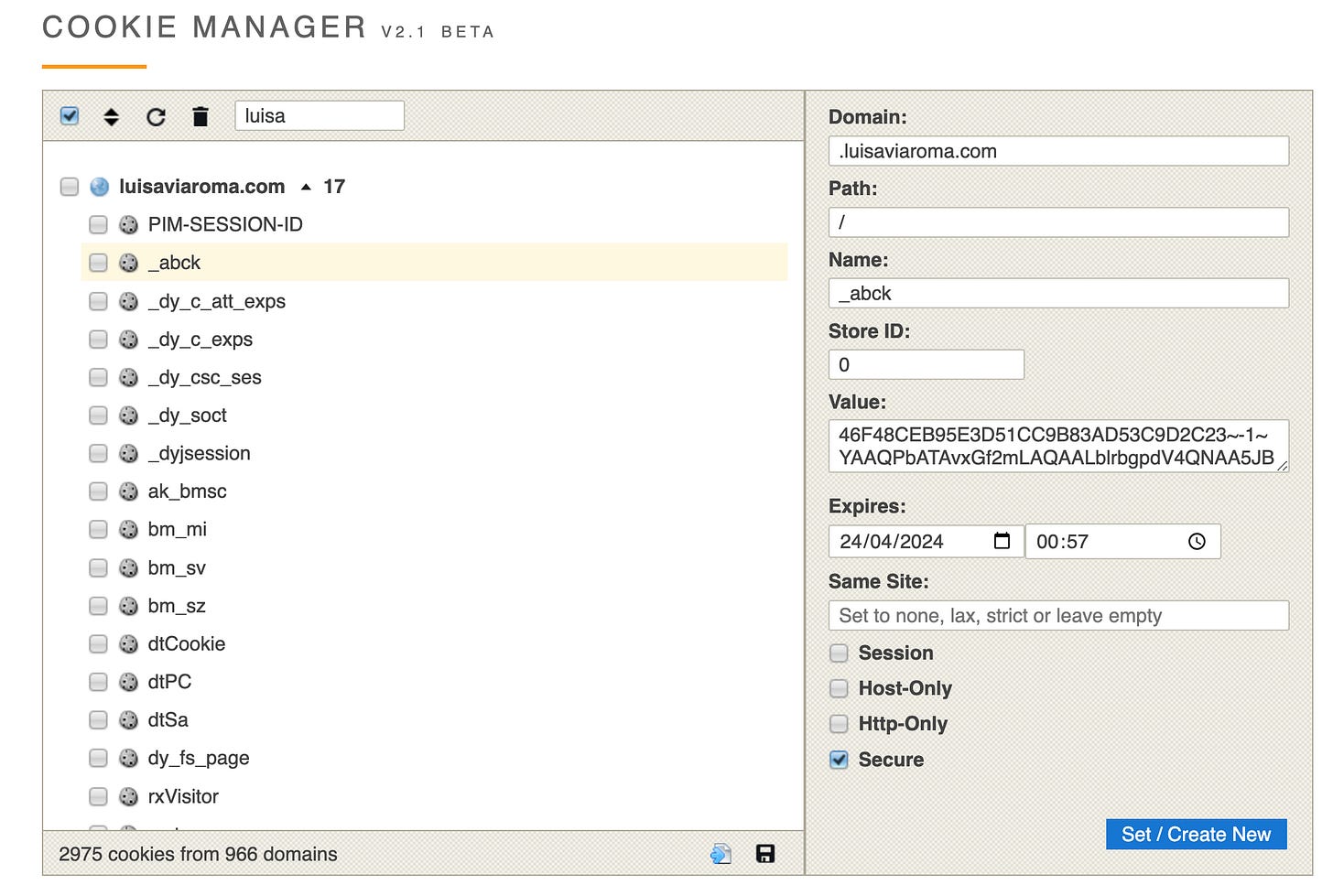
As mentioned at the beginning of the post, I’ve made the scraper work again, probably not in the most advanced and sophisticated way, but it’s for sure cost-effective, and, from the implementation, it did not present again any issues. And the solution is quite trivial: analyzing the Akamai cookies on my computer, I’ve seen that some of them are set to expire in six months.
[
{kind=link}
Quite interesting, why don’t simply pass this valid cookie in our Scrapy spider, faking we’ve already bypassed the first control by Akamai?
Believe it or not, this trivial idea made my scraper work and I’ve been able to scrape this website on a daily basis for a week now, without any issue. Life is good.