THE LAB #3: Scraping Cloudflare protected websites
Excerpt
Without buying any external software, for real.
Here’s another post of “THE LAB”: in this series, we’ll cover real-world use cases, with code and an explanation of the methodology used.
In the future, this kind of content will be available only to paying subscribers. Being one of the first of the series, this one will be available for free until the 2nd of Oct 2022, then will be behind a paywall.
Being a paying user gives:
-
Access to Paid Content, like the post series called “The LAB”, where we’ll go deep diving with code real-world cases (view here as an example).
-
Access to the GitHub repository with the code seen on ‘The LAB”
-
Access to private channels on our Discord server
But in case you want to read this newsletter for free, you will always get a post per week about:
-
News about web scraping
-
Anti-bot software and techniques insights
-
Interviews with key people in the industry
And you can always join the Web Scraping Club Discord server
Enough housekeeping, for now, let’s start.
What is Cloudflare?
Cloudflare NET 0.50%↑ is an American company, based in San Francisco, offering several services like DDoS mitigation services, Distributed DNS, Content Distribution Networks, and also anti-bot protection for websites.
On its anti-bot protection it uses both passive bot detection techniques like TCP, TLS, and HTTP fingerprinting and also active ones like Canvas fingerprinting and CAPTCHAs. On top of all this, it queries the browser to identify any automation tool and monitors what happens on the page, to track mouse movements and all actions that can make a bot detectable.
At this moment, it’s one of the toughest solutions to bypass in a web scraping project. I think anyone who has some experience in this field has encountered this screen at least once in his life.
[

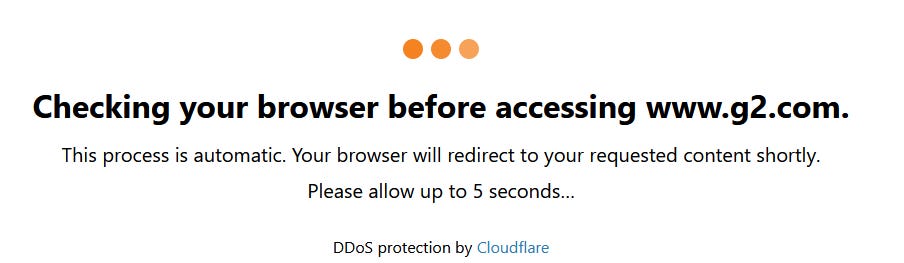{kind=link}
Since there’s no silver bullet to avoid being blocked, we’ll see 3 similar but not identical solutions for scraping 3 different websites:
As usual, we’re scraping public product price data, without logging in, and at a speed that doesn’t harm the business of the target website.
General Approach
In the past, I’ve found several Python packages on GitHub that promise to bypass Cloudflare protection by reverse-engineering its functioning.
In my opinion, while I love the hacking part inside these solutions, these tend to be less stable in the long run. A small change in the algorithm makes the package unusable and you need to wait for the patch to be found, but usually, you don’t have that time.
Another trick I’ve read around is trying to bypass Cloudflare by connecting directly to the IP of the web server of the website. It can be found, if you’re lucky enough, with services like SecurityTrails, which exposes the history of the DNS of a certain address. If the IP that the server had before going to Cloudflare isn’t changed and it is still configured to accept connections from the outer world, you can try to connect directly to it.
My approach to this challenge is instead to try to mimic a real user, as realistic as possible, to make the scraper undetectable from a real user, or at least close enough to enter the “tolerance range”.
As far as I understood from the outside (I’ve never worked on configuring Cloudflare so these are only suppositions), Cloudflare can be configured to be more or less restrictive on the anti-bot front. All the websites must accept compromises between the zero tolerance of bots, at risk of interrupting the browsing of several users with older hardware, shared IPs, and so on, and full exposure to DDoS attacks.
On top of all this, often websites have more than one anti-bot solution installed (as an example SSENSE has both Cloudflare and PerimeterX).
This is why in this post, given 3 websites protected with Cloudflare, we will see slightly different solutions.
P.S.: to avoid readability issues I’m screenshotting part of the code instead of inserting it inside the text. Paying subscribers can find the code inside the GitHub repository I’ve privately shared.
Our starting point
We’ll start our experiments with a python script per website, which call Playwright and its stealth plugin. In each script we will open firstly the Google home and then the home page of the websites, making then a random mouse movement on the page.
[
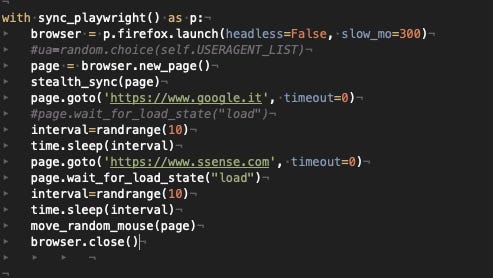
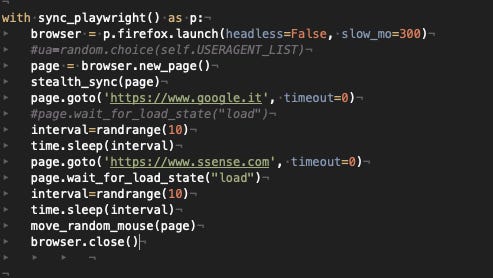{kind=link}
For all the 3 websites this configuration works and we can open without any issue the home page. And we could do it both with Firefox and Chromium and even without using the stealth plugin.
[
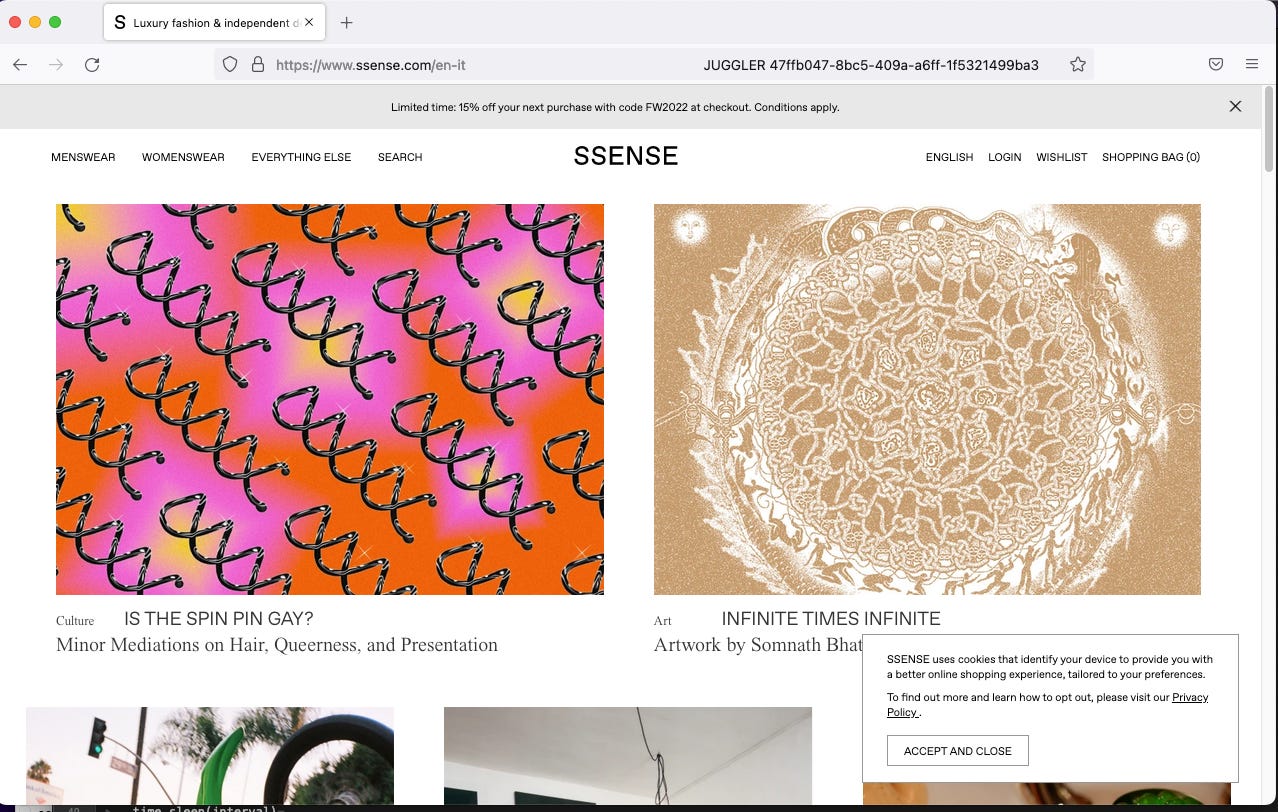
{kind=link}
But we will see that things will change as soon as we start to crawl the websites.
SSENSE
Let’s try to get all the Men items from a country. To limit the number of requests to the website, we’ll crawl only the catalog pages, trying to extract everything from the JSON inside the HTML code.
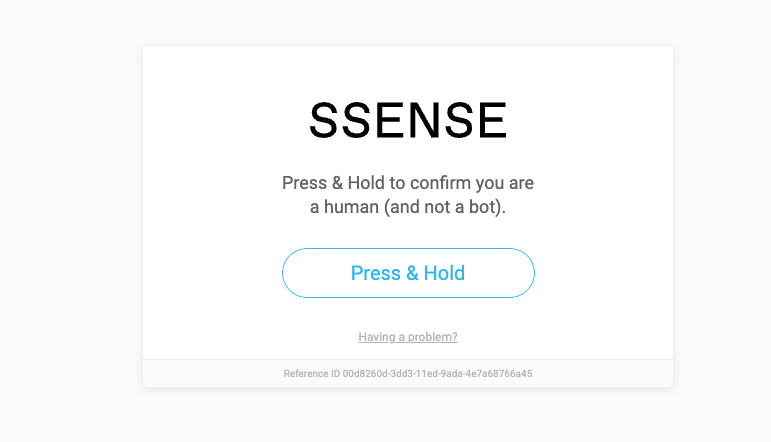
If we try to go straight to the man catalog, we immediately get blocked by PerimeterX when browsing using Chromium + stealth, while using Firefox + stealth works randomly.
[
{kind=link}
Let’s choose Firefox and start from the home page again, and then click on the Menswear menu. Adding some random mouse movement on every page and a random time interval between each page request, the scraper slowly browses all the pages of the menswear category.
[
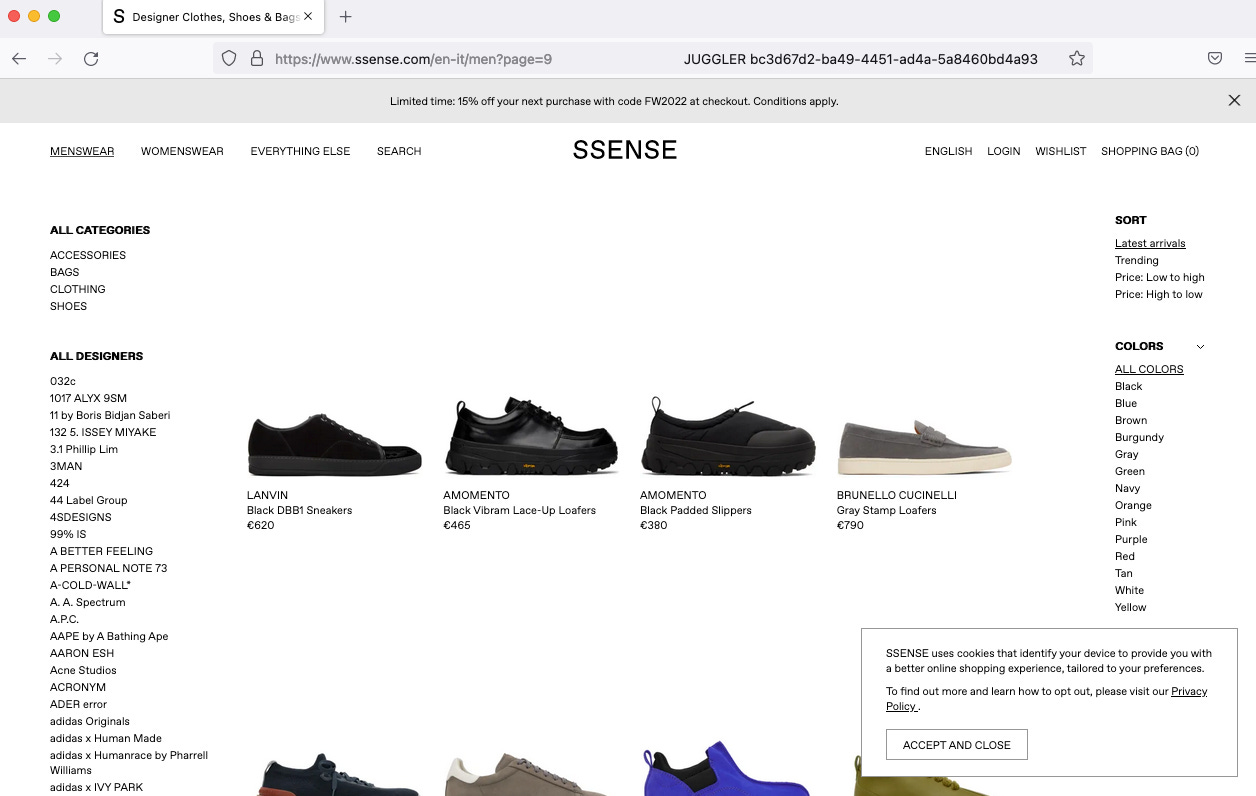{kind=link}
An improvement that can be made for better memory management is to split the execution between the different subcategories of the website (accessories, bags, clothing, and shoes ), closing the browser when the category is fully crawled.
Key Features
-
Start from the home page, not the catalog
-
Use Firefox
-
Random mouse movement and sleeps
BROWNS
Again we choose to crawl the whole man catalog of products, so we declare the categories as a first step.
For each category, we open a browser page, go to Google, Browns’ homepage, and then we start crawling the category, using the same configuration of Ssense scraper.
Let’s start with Firefox and the stealth plugin and see what happens.
[
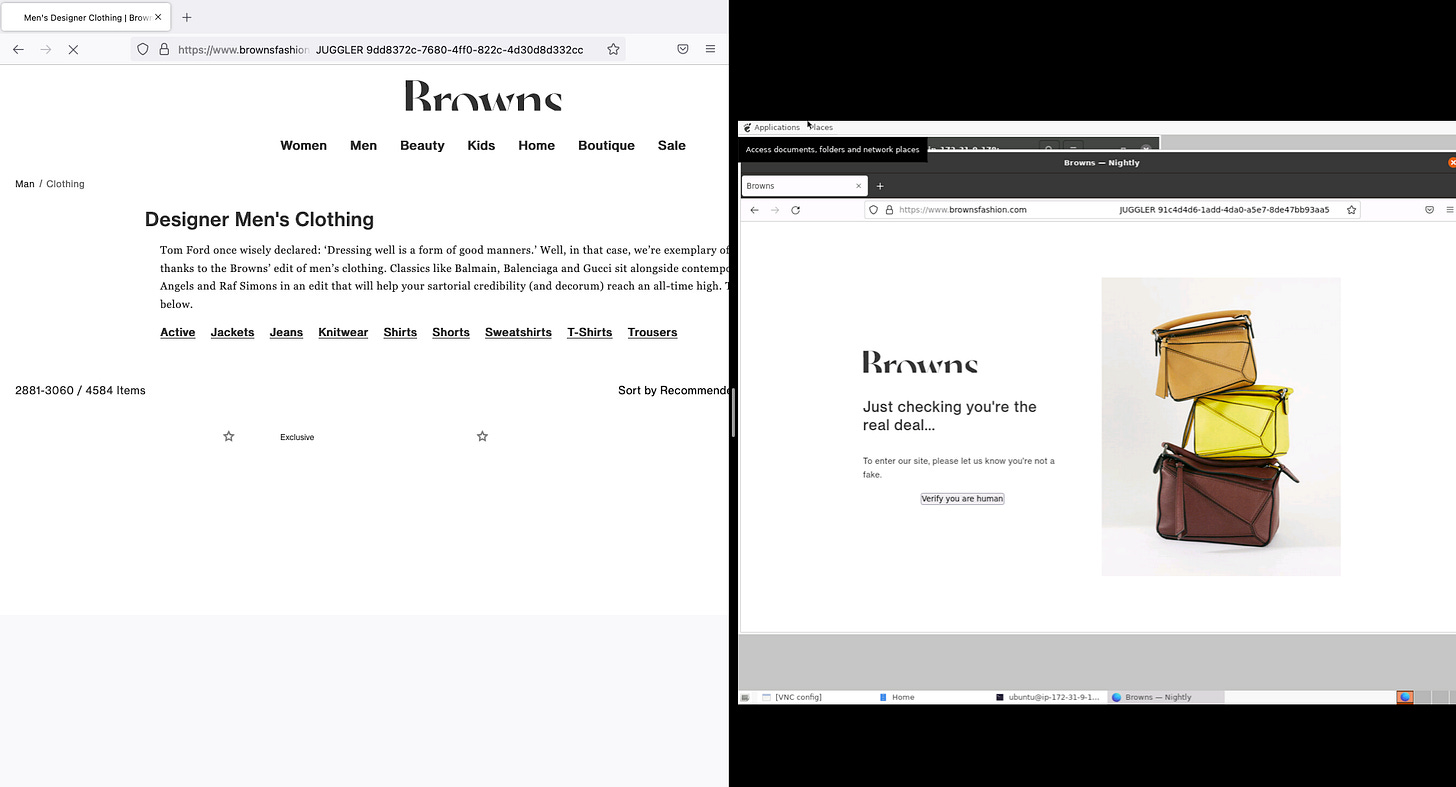
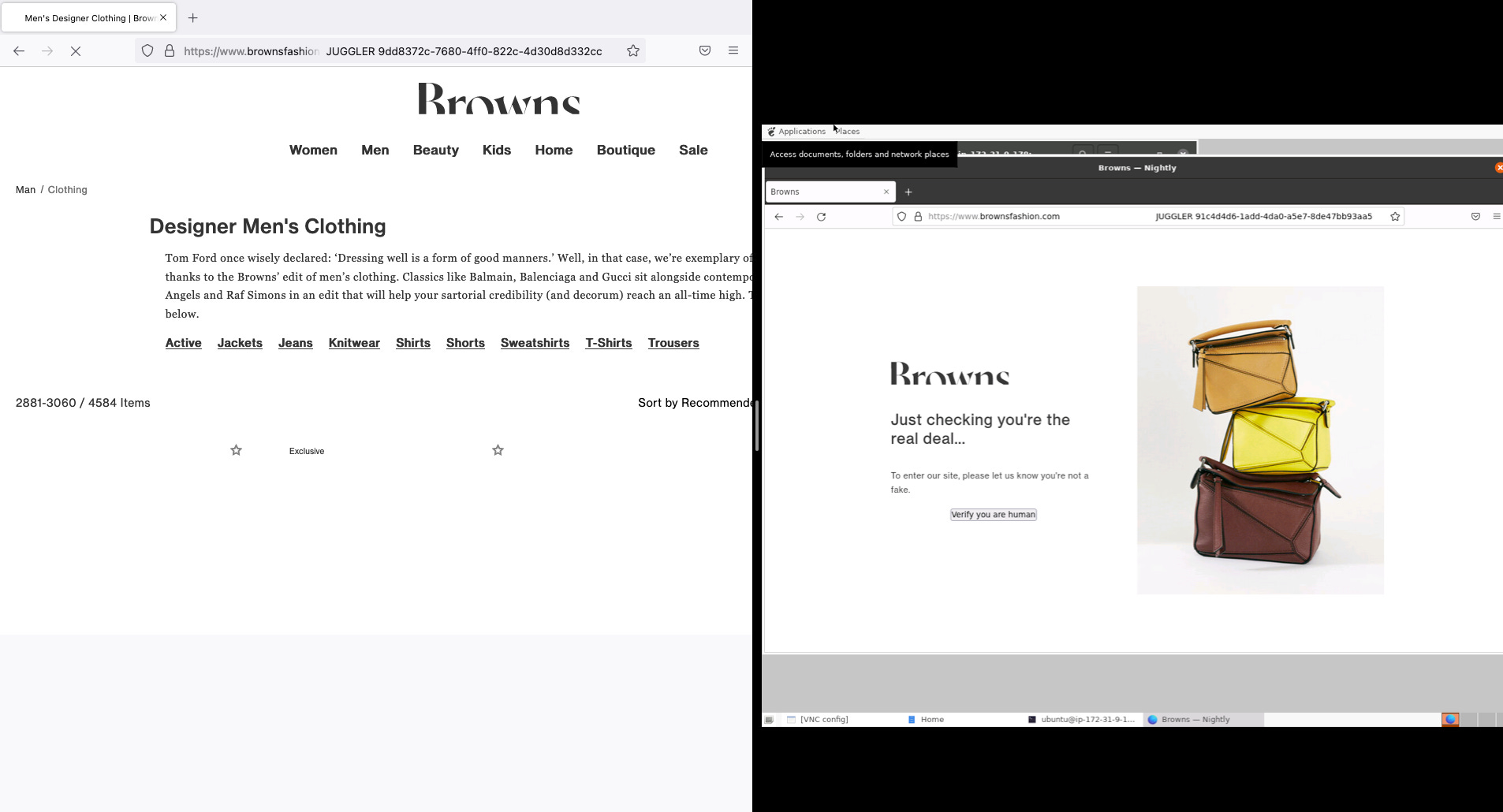{kind=link}
On my local machine, it works perfectly but the problems start on EC2 (left side of the image), where as soon as I start to crawl a subcategory, I receive a captcha (right side).
This is due to the fingerprinting technique used by Cloudflare that, once recognized the hardware where the scraper is running, raises some red flags and triggers the blocks. We must improve then our camouflage to mimic even more a real user.
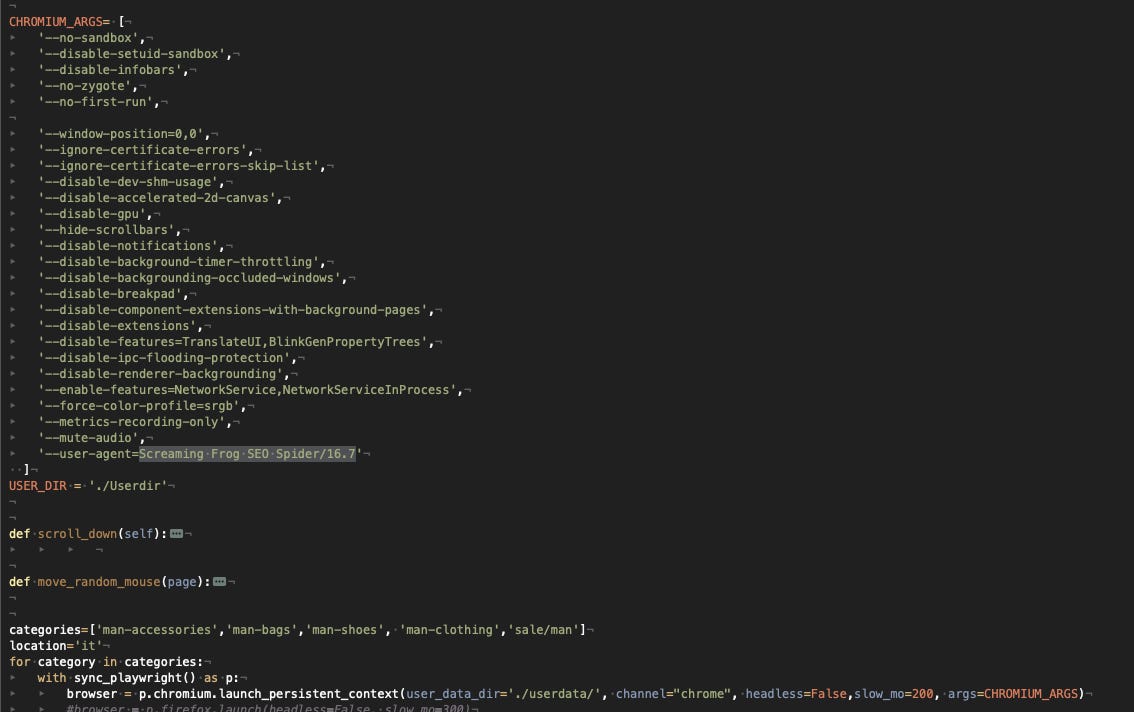
To make a long story short, what I’ve implemented after hours of trials and error is using an instance of Chrome (not Chromium), with a persistent context and a user data folder where to store cookies and navigation data and a set of arguments that I’ve found out to be effective.
[
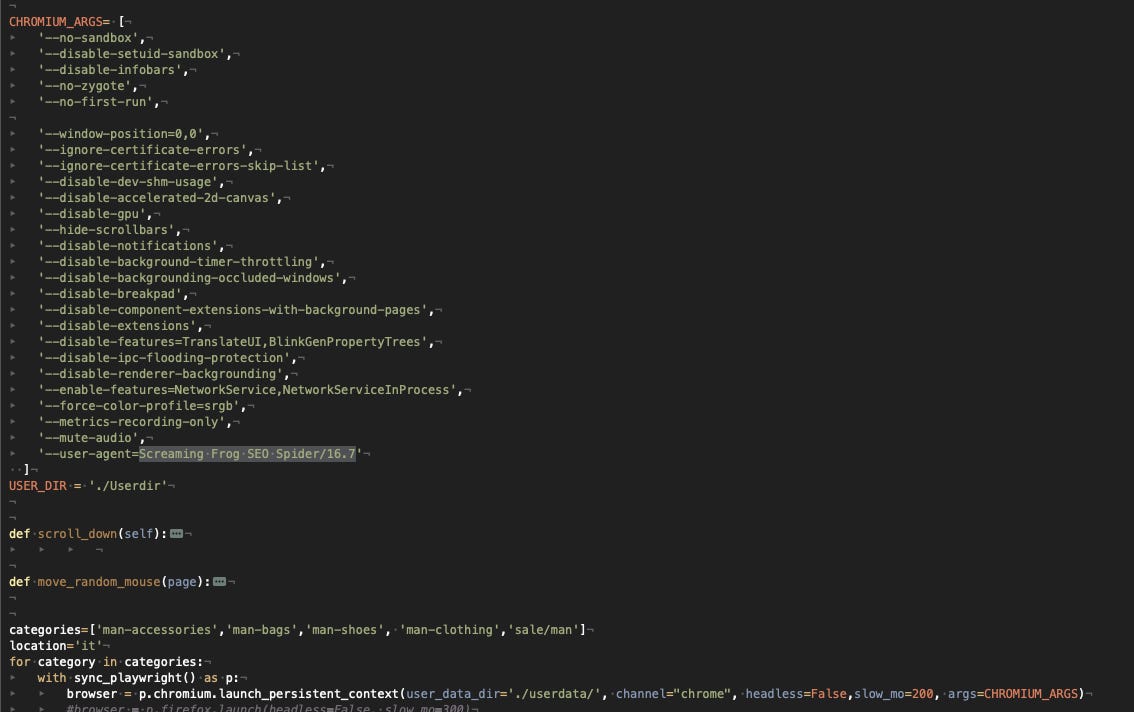
{kind=link}
The most counter-intuitive option is the User Agent: instead of using the User Agent of the latest version of Chrome, I just used one of the marketing tool called Screaming Frog, even if there was no sign of it in the robots.txt file. I assume that the standard Chrome User Agent string triggers some more checks that my scraper didn’t pass.
Thanks to these tweaks, the scraper now runs also on Ec2 instances.
Key Features
-
Start from the home page, not the catalog
-
Use Chrome with a persistent context
-
Use Screaming Frog User Agent
-
Random mouse movement and sleeps
ANTONIOLI
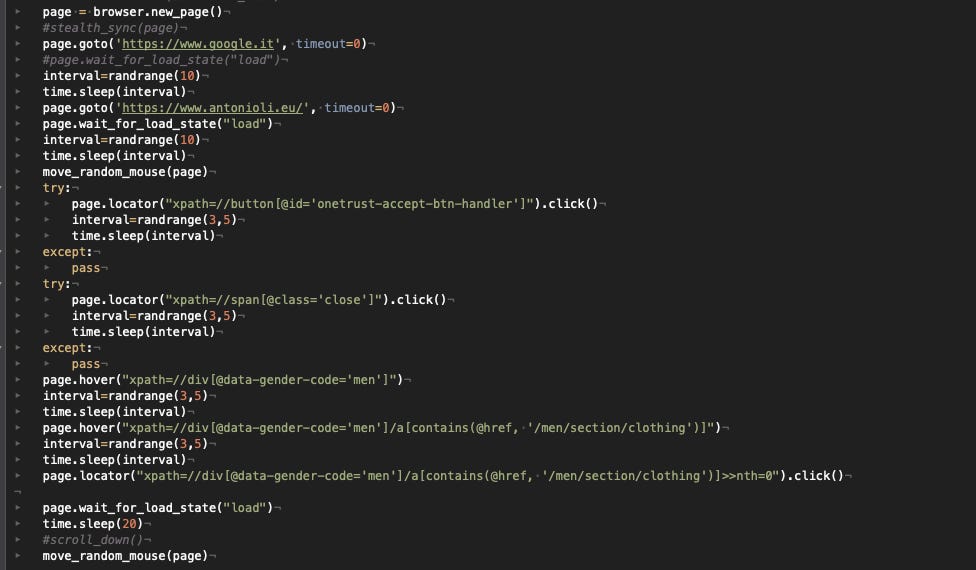
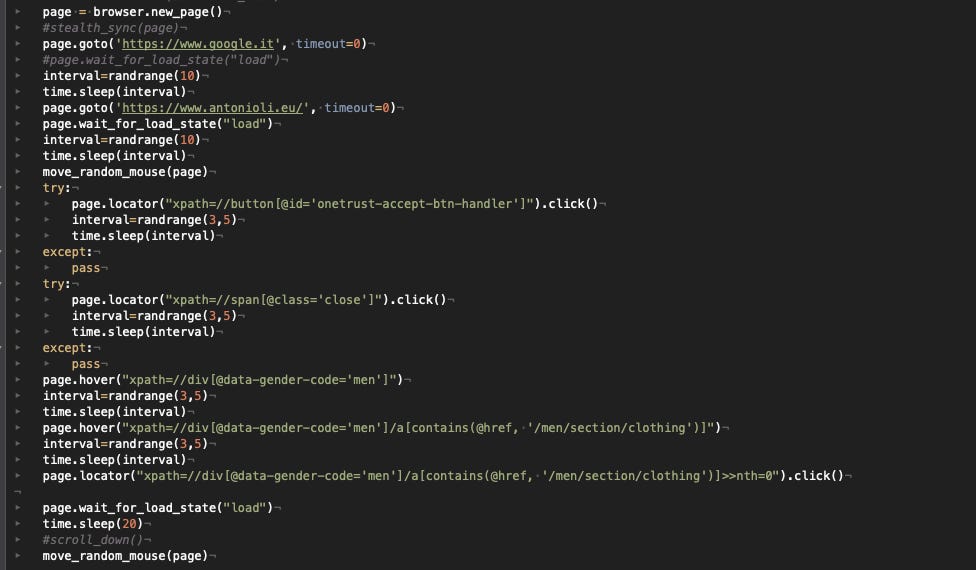
The starting configuration for the Antonioli website is pretty similar to the one of SSENSE. Chromium does not work, so we’ll use Firefox, we’ll scrape one subcategory of items per run, and there’s no need of using the stealth plugin.
The main difference can be found when we need to turn the pages: instead of passing the URL of the next page, we need to click on the right arrow at the bottom, otherwise, we get blocked after a few pages.
In this case, it seems that Cloudflare is configured to consider more user interaction with the website rather than other parameters, especially when running on AWS. After we enter the home page, as soon as we break “the flow” of clicks, we get blocked. So we cannot pass the URL of the item category we want to scrape but we must click on it, and the same is when paginating the catalog.
[
{kind=link}
I’ve also added then the option to accept the cookies on the lower banner and close the newsletter pop-up, if any.
Key Features
-
Start from the home page, not the catalog
-
Use Firefox
-
Don’t break the “click flow”
-
Random mouse movement and sleeps
Key Takeaways
As we said at the beginning of this post and seen with the examples before, there’s no silver bullet to bypass Cloudflare when scraping.
Depending on the website configuration, you will need to improve the “stealth” capabilities of your bot making it behave like a human being.
For sure it requires a lot of effort to understand what’s the key to scrape consistently each website over time even if, quoting Yoda
[

{kind=link}
Enough for today, for the full code of the scraper used in this example, paying subscribers can access the Github repository and get it, while if you need some tips and hints, you can always enter our discord server.
Just as a reminder, for our readers, we have a special discount code 50% off for the Extract Summit happening the next 29th of September in London**:** use the code thewebscrapingclub when buying your tickets.
[

{kind=link}
Is any of our you working on something spectacular in web scraping and want to share with us? please write to pier@thewebscraping.club and let’s talk about it! You could be in the next interview.