THE LAB #28: Deep dive on inventory levels tracking
Excerpt
Lowe’s: A real world example of scraping inventory level from an heavily Akamai-protected website
In the previous post of The Lab, we saw some examples of websites that exposed their inventory levels via API and made some hypotheses on how to use this information.
In this episode, instead, we’ll see another website of a well-known publicly traded company and create a scraper to extract this information, with all the code available in our GitHub Repository available for paying subscribers.
If you’re one of them but don’t have access to it, please write me at pier@thewebscraping.club with your GitHub username so that I can give you access.
Lowe’s home improvement: a brief history
Lowe’s (LOW 0.24%↑) is the second home improvement retail chain in the US, with more than 2100 stores operating in North America.
Its product assortment ranges from furniture to animal care and this makes the website an interesting target to monitor.
[

{kind=link}
Being so popular and with a large availability of different products and brands, the analysis of its inventory can be used not only to evaluate Lowe’s profitability but could be a proxy for evaluating the distributed brands and, why not, a portion of the consumer price index.
Today, Lowe’s is the 57th most valuable company in the S&P 500, so it’s quite an interesting target website to monitor.
Website preliminary analysis
Now we assessed the importance of Lowe’s for the home improvement industry and its operators, let’s try to see if we can extract some valuable insight from its website.
One common feature of companies’ websites with both physical stores and online presence is the “pick up in store”.
This service implies that the website should be aware if an item is available in every store, so probably a call to some kind of API is made to get this information.
Each website threats this information differently, there might be some websites that check only if an item is available or not, while others know the exact number available of a single store, showing it also to the customer. That’s the case of Leroy Merlin in Italy, a popular home improvement retailer.
[

{kind=link}
Leroy Merlin Italy
In other cases, similarly to what we’ve already seen in our IKEA post, the exact number of items available is hidden in the internal API calls a website makes to check the inventory levels.
After playing around on the website for some time, I found out that this is the case also for Lowe’s website. When scrolling the product list page of a category, we can intercept from the console an API call that returns a JSON with some exciting data.
[

{kind=link}
Given that the quantity changes when we select another store and refers to the pickup option, we can reasonably think that the TotalQty number highlighted refers to the inventory level for the selected product in a particular store or warehouse.
Now we have discovered that there’s valuable information hidden between the API calls, we need to understand how difficult is to extract it at the desired scale.
From a quick view on Wappalyzer, the only anti-bot solution protecting the website is Akamai, so probably we could use Scrapy with a good proxy rotation.
[

{kind=link}
Implementing the scraper
Inspecting the website’s behavior, we can say that we’ll need two key pieces of information to get the most out of it.
The API call mentioned before has this format:
https://www.lowes.com/pl/Refrigerators-Appliances/4294857973/products?offset=24&adjustedNextOffset=22&nearByStores=2291,2496,2265,2536,2514&ac=false
We have the product list category as a starting point and then the codes of the stores where to check the inventory.
Given this, we can split the scraping task into two parts:
-
building the store list
-
given a category and a store, crawl the whole category using the API
Building the store list
This is the easiest part, using the right tools. I’ve noticed that simply using residential proxies to rotate IPs was not enough, since my Scrapy requests were blocked from the first one.
So I’ve decided to use Oxylabs’s Unblocker to create the store master table, starting from the Lowe’s store directory and iterating in every state to crawl all the cities.
In the code you’ll find on the GitHub Repository for paying readers, you will find a filter on NY stores but it’s only to limit the requests to make since it’s not useful for the scope of the article to crawl all the 2000+ stores.
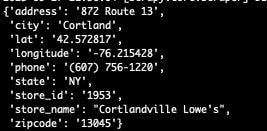
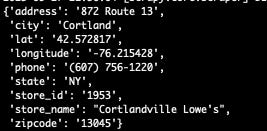
The output of the first scraper, called stores, will contain the following info:
[
{kind=link}
To launch it correctly, after changing the file proxy.txt using your preferred proxy provider, you just need to run the following command:
scrapy crawl store -o stores.txt -t csv -s PROXY_MODE=0 -s PROXY_LIST='proxy.txt' -s REMOTE_PROXY_USER='MYUSER' -s REMOTE_PROXY_PWD='MYPWD'
where the REMOTE_PROXY_USER and REMOTE_PROXY_PWD parameters will substitute the USER and PWD variables in the proxy.txt file.
Crawling a product category
Here’s the hardest task.
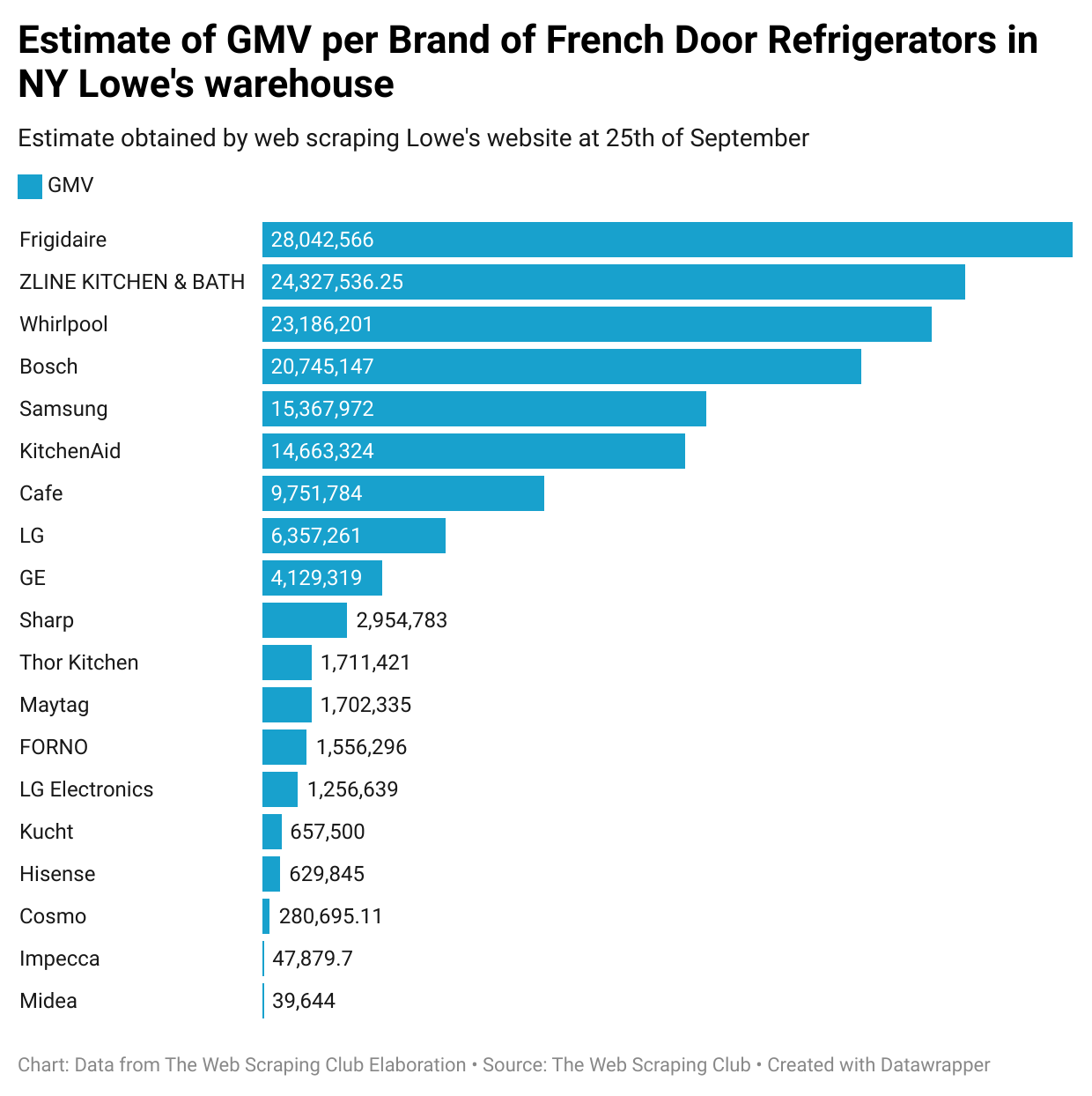
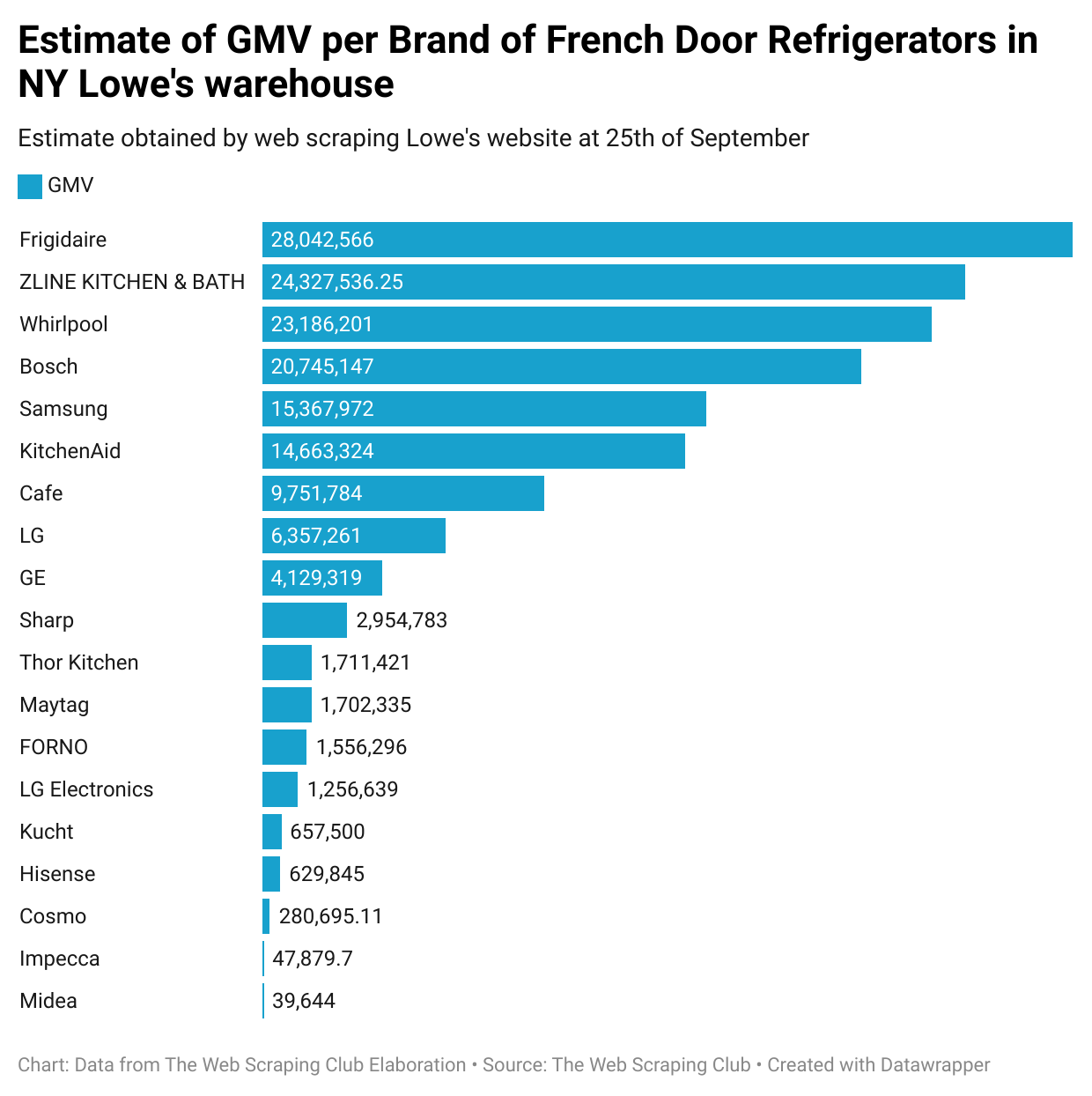
First, the website shows you only twenty-five pages at max for each product category, so we need to select one product niche under the 600 (24 items per page x 25 pages) limit. For this test, I’ve selected the French Door Refrigerator category.
One other challenge is that the API mentioned in the previous paragraph, which returns the data we need, doesn’t work when called by a simple GET request, and didn’t find a way to call it properly, but it’s not that bad. Its results are also in the HTML of the page, so we need only to extract the JSON containing the stock levels from there.
However since we cannot call the API, where one of the parameters is the store ID, we need to find a way to change the pickup store from the top left corner of the website.
[

{kind=link}
After some tests, I’ve decided to use Playwright and its contexts to solve this challenge in an elegant and without the aid of any commercial solution.
I’ve selected two random stores in NY state from the previous execution and passed them as input to the new script.
stores=["1709;Bay Shore Lowe's;NY;Bay Shore;800 Sunrise Highway;(631) 954-9001;40.727128;-73.281154", "0523;Utica Lowe's;NY;Utica;710 Horatio Street;(315) 793-3812;43.126065;-75.224919"]
for line in stores:
store, name, state, city, address, telephone, lat, lon = line.split(';')
browser = p.chromium.launch( executable_path='/Applications/Brave Browser.app/Contents/MacOS/Brave Browser', headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"])
context = browser.new_context(
geolocation={"longitude": float(lon), "latitude": float(lat)},
permissions=["geolocation"],
)
context.set_geolocation({"longitude": float(lon), "latitude": float(lat)})
page = context.new_page()
The coordinates of the stores are stored in the geolocation attributes of the Brave browser instance.
After the initial IP check that assigns me to a store, being out of the USA, I could change the preferred one by asking the website to show me the nearest store around me (or better, around the coordinates I’m passing in the browser).
[
{kind=link}
Given the list, I can confirm the right store by selecting the one with the correct store ID and finally browsing the website with the proper pickup store set.
From now on, it’s a piece of cake: we simply need to browse the category until the final page and parse the JSON containing the stock levels.
One last peculiarity: if you have a look at the code on the GitHub repository (available only to paying readers, if you’re one of them and don’t have access, write to me at pier@thewebscraping.club to get access), you may have noticed I reload the page after every click on the next button.
Without doing so, for some reason, the JSON remains stale and I would get the same results as the first page.
Final remarks
I find that inventory level tracking is one of the most exciting use cases for web scraping, and apart from the finance world, it’s still very underrated.
It’s a reverse engineering process, both on the technical aspects of how to gather this data, but also on how to interpret it.
As an example, taking these two stores in NY, I suppose the stock level is referred to as a sort of central warehouse in the state rather than a single store, seeing the volume and the few differences between the two extractions.
Extracting the maximum value from this data could be challenging since it should be monitored for at least 2-3 years but in the meantime the source could change and the information is no longer accessible.
But despite these efforts, I still cannot believe that every CEO in the home improvement industry doesn’t have a report with this kind of data on his table.
[
{kind=link}