THE LAB #2: scraping data from a website with Datadome and xsrf tokens
Excerpt
A real world use case of a simple scraper that does not get blocked by Datadome
Here’s another post of “THE LAB”: in this series, we’ll cover real-world use cases, with code and an explanation of the methodology used.
In the future, this kind of content will be available only to paying subscribers. Being one of the first of the series, this one will be available for free until 22th of Sept 2022, then will be behind a paywall.
Being a paying user gives:
-
Access to Paid Content, like the post series called “The LAB”, where we’ll go deep diving with code real world cases (view here an example).
-
Access to the Github repository with the code seen on ‘The LAB”
-
Access to private channels on our Discord server
But in case you want to read this newsletter for free, you will always get a post per week about:
-
News about web scraping
-
Anti-bot software and techniques insights
-
Interviews with key people in the industry
And you can always join the Web Scraping Club Discord server
Enough house-keeping for now, let’s start.
What is Datadome?
Datadome Bot protection is one of the key players in the anti-bot software industry.
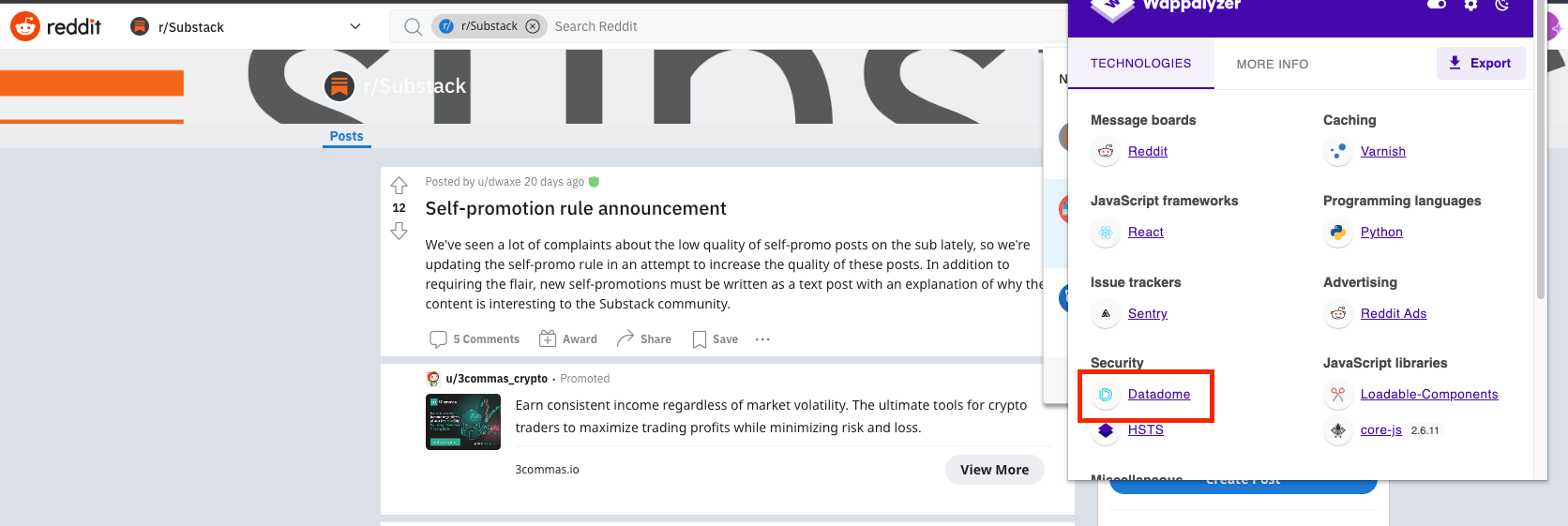
As stated on their website, the solution is used on several important websites such as FootLocker, Rakuten, and even Reddit, as you can see from the picture below.
[

{kind=link}
Datadome on Reddit
So, sooner or later, in your life as a web scraper, you’ll surely face one website protected with this technology.
These days I needed to update a scraper that eluded Datadome so it’s a good time for writing the process that allowed me to scrape the data from this website.
Are you looking for a Birkin?
In case you know what a Birkin is, you probably understood that the website in question is Hermes.com. For the others, a Birkin is one of the most iconic bags crafted by the Maison Hermes and it costs like a supercar (and no, it’s not sold online anyway).
[
{kind=link}
From a quick analysis of the network tab of the browser, we can see that by browsing the products in every category, we call an internal API that shows the product details we need.
Let’s start with the basic stuff
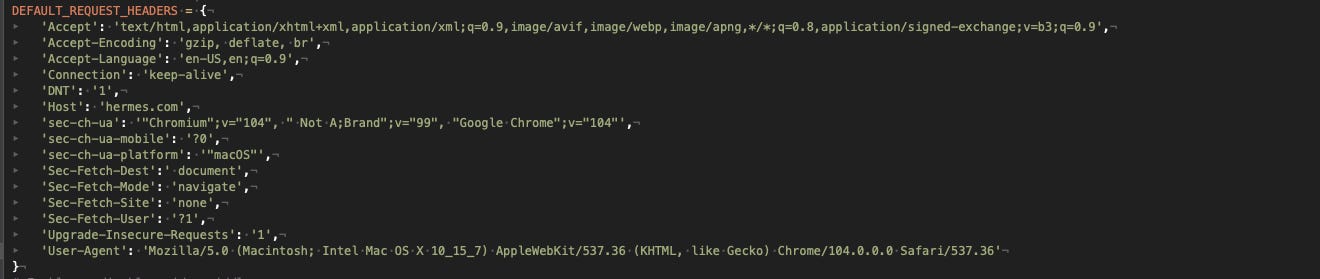
Let’s start with our standard Scrapy spider and see if we can get inside the website, after some make-up to our DEFAULT_REQUEST_HEADERS property.
[

{kind=link}
And soon we can see Datadome at work. We got redirected and locked out of the website, while on the browser the redirect leads to the Home page of the website.
[

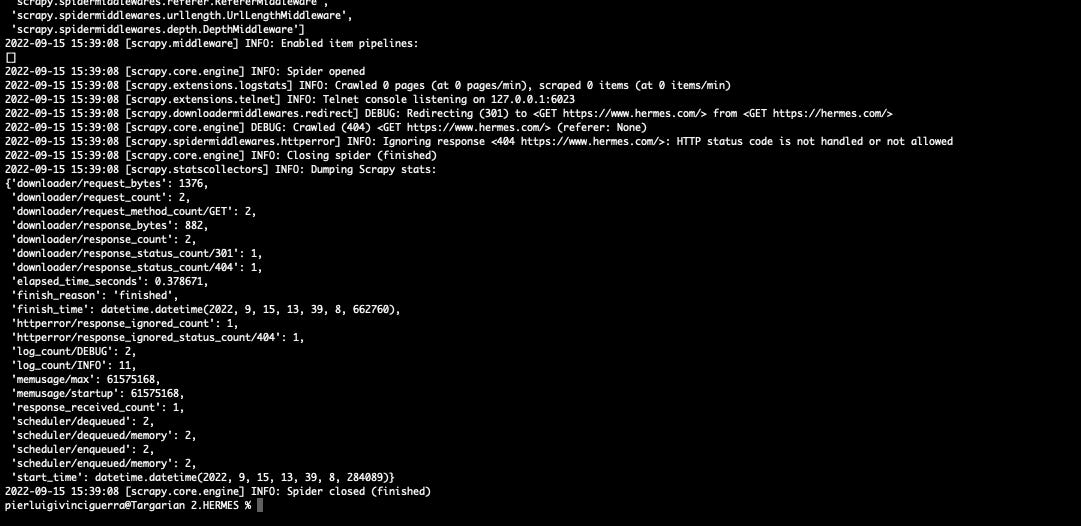{kind=link}
A different path.
Hermes does not have an official App but I can use the same procedure explained in the first post of THE LAB to see how the website behaves when accessed by mobile.
The behavior of the website seems more or less the same but, mocking up the scraper as a mobile phone, things get interesting.
[

{kind=link}
[
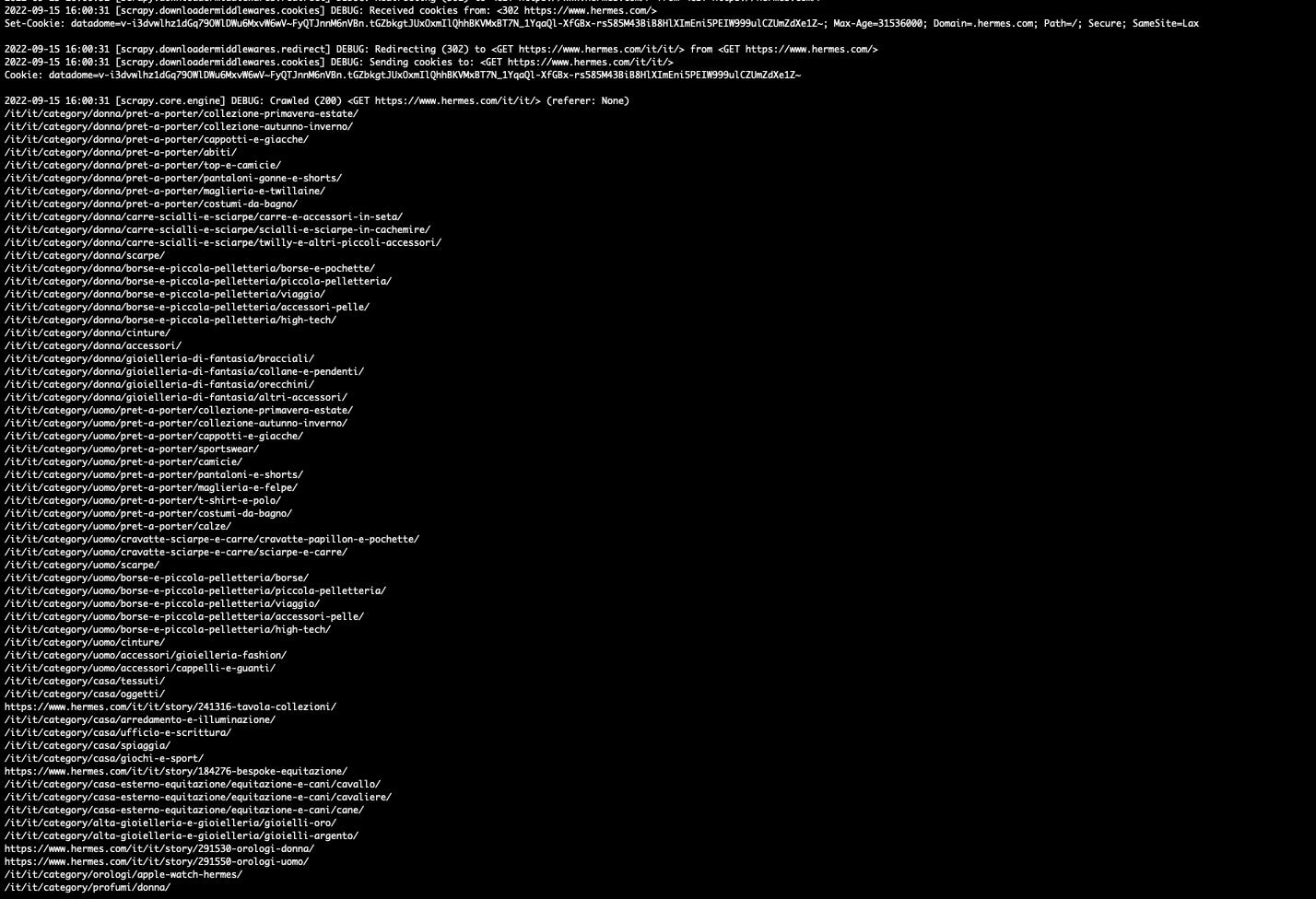
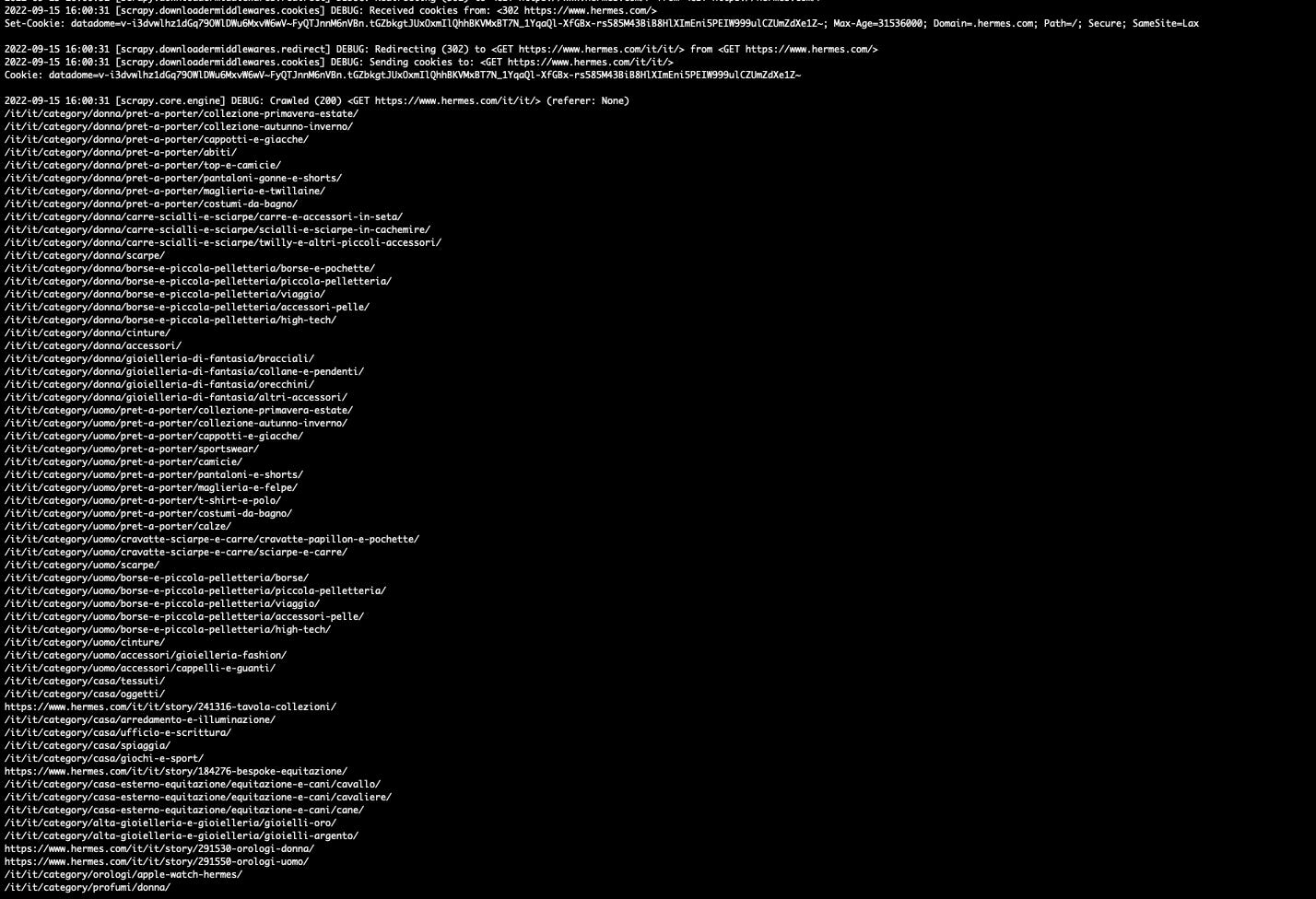{kind=link}
I can enter the homepage now and, parsing the JSON in the HTML, I can crawl the whole category tree now! And now in my Cookies, there’s also stored a precious Datadome token, my passe-partout for the website.
I don’t believe this is the standard Datadome behavior, I suppose the configuration of the Hermes installation leaves a backdoor open for mobile phones, to get the navigation more fluent also when there’s a lack of connectivity. It’s the usual trade-off between site usability and the protection of data that is already public and should not need to be behind any barrier.
We’re only halfway
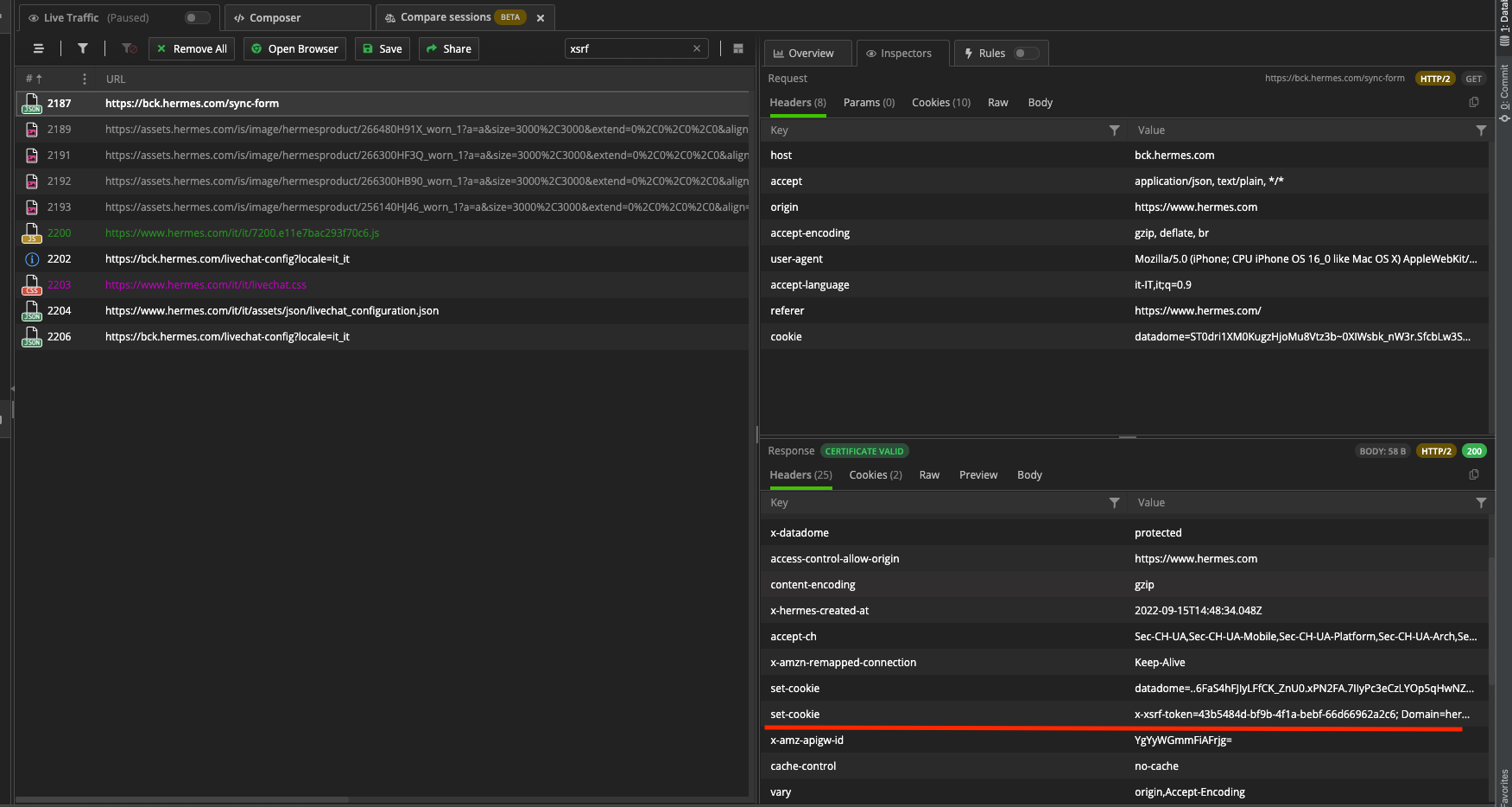
Now we can crawl all the categories, we need to get to the internal APIs to get the data we need. A simple GET request to the endpoints leads to a 403 error since we need an XSRF token inside our Cookies.
Websites usually protect their API endpoints using this kind of technique to avoid access to an unauthorized person. But since we don’t have logged in to the Hermes website, in this case, the token should be generated on-the-fly somewhere while we browse.
Going back to Fiddler and with some back and forth on the website from the mobile, I’ve found a function that generates it before every API call. Yeah!
[
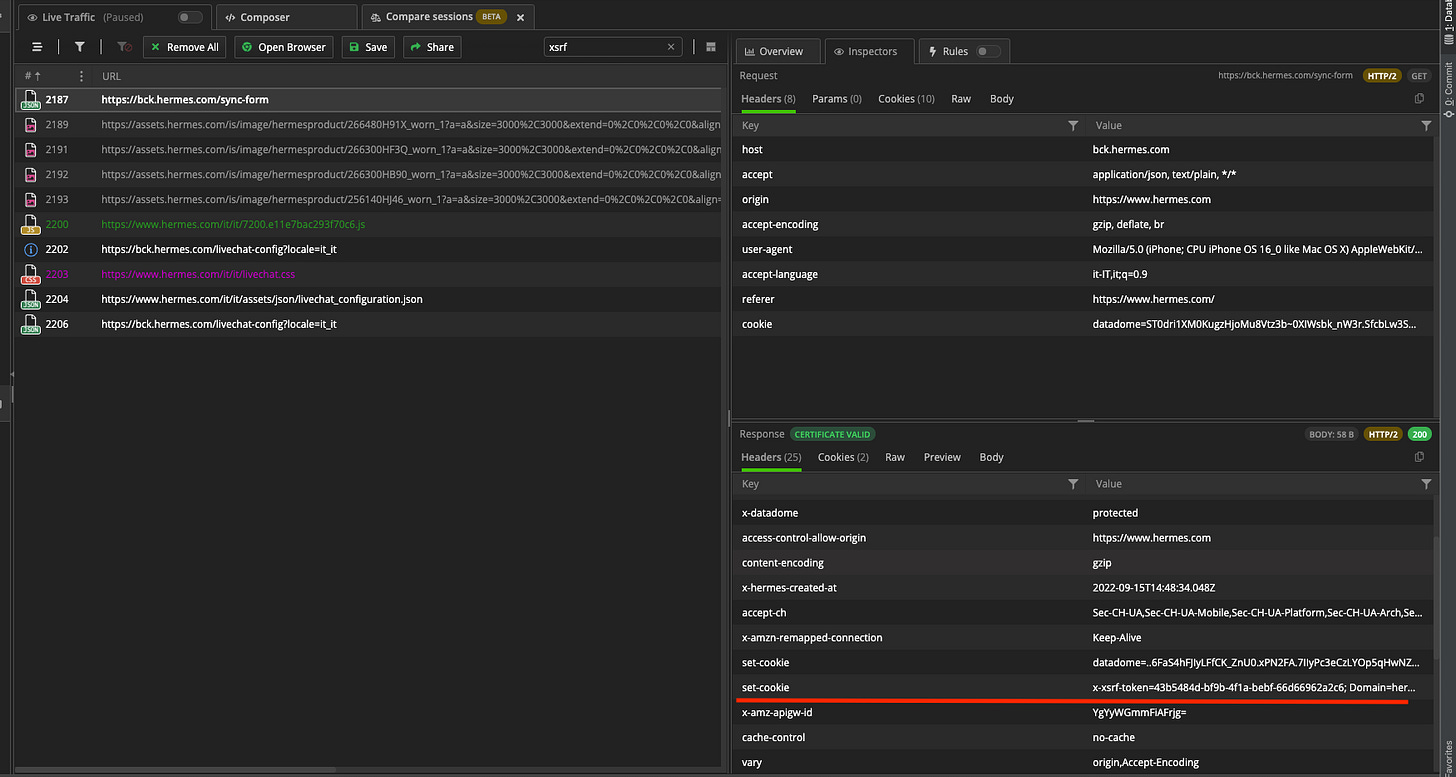
{kind=link}
The final touches
So basically what we need is to iterate, with proper request Headers, between the “syncform” API call to get the token, the product API, and then back to the “syncform” for a new token and then again to the product API new request.
[
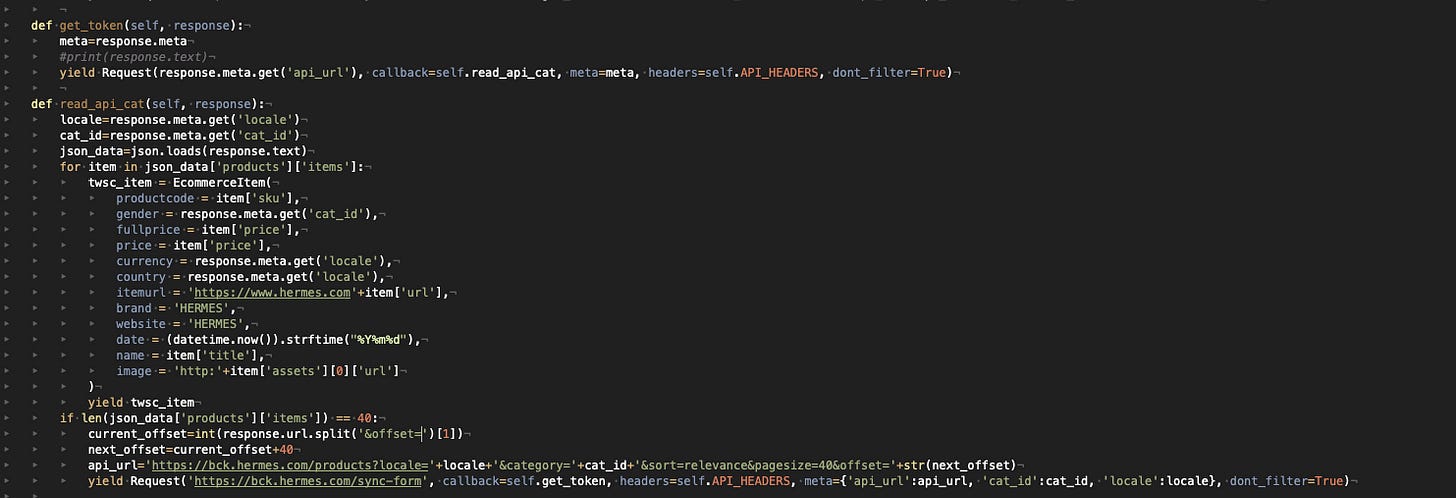
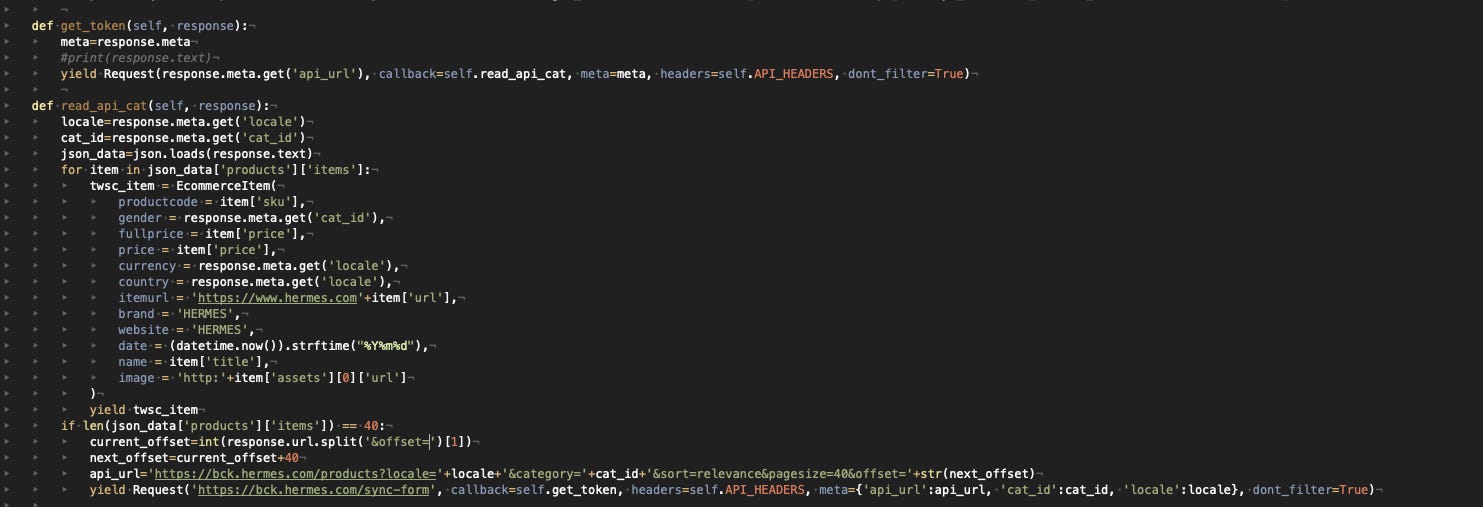{kind=link}
Key Takeaways
Websites and anti-bot solutions could behave differently according to the entry point. What doesn’t work on the website accessed from a PC maybe can work when our scraper impersonates a mobile or an app.
If you can access the data exposed by an API simply by browsing a website, your scraper can do it too. Take your time studying the behavior of the target website and you’ll find a way to scrape it.
For the full code of the scraper used in this example, paying subscribers can access the Github repository and get it, while if you need some tips and hints, you can always enter our discord server.
Just as a reminder, for our readers, we have a special discount code 50% off for the Extract Summit happening the next 29th of September in London**:** use the code thewebscrapingclub when buying your tickets.
[

{kind=link}
Is any of our you working on something spectacular in web scraping and want to share with us? please write to pier@thewebscraping.club and let’s talk about it! You could be in the next interview.