THE LAB #13: Managing a fleet of scrapers with Scrapeops
Excerpt
Using Scrapeops dashboard to monitor your web scraping operations in large web scraping projects
This article is sponsored by Serply, the solution to scrape search engine results easily.
[

{kind=link}
Serply
Web Scraping Club readers can save 25% on all SERP scraping plans by using the code TWSC25.
Welcome to the new episode of The Lab on The Web Scraping Club, where we’ll see how to manage a fleet of scrapers with Scrapeops, a web scraping commercial solution that allows you to have a dashboard for the scrapers’ execution, a job scheduler, and a proxy aggregator.
Note: I don’t have any commercial agreement with Scrapeops or referral program linked with them, I just find this could be a useful solution for large web scraping projects.
Large web scraping projects and their challenges
Web scraping has become an essential tool for many businesses and organizations to gather data from the internet. However, large web scraping projects pose unique challenges that require careful planning and execution. One of the most significant challenges is monitoring hundreds of scrapers and their executions, as well as scheduling the spiders using tools like Scrapy. In this blog post, we will discuss these two challenges in detail and provide some solutions to overcome them.
Monitoring Hundreds of Scrapers and their Executions
Web scraping projects often require the scraping of multiple websites, and for each website, multiple pages need to be scraped. This means that a large project can involve hundreds of individual scrapers, each with its own set of requirements, settings, and parameters. Monitoring the status of these scrapers and their executions can be a daunting task, especially if you are relying on manual checks. Most web scraping frameworks, including Scrapy, have built-in logging capabilities that allow you to track the progress of your scrapers and identify any issues that arise. By reviewing the logs regularly, you can catch and address errors before they become significant problems. But doing it manually for hundreds of scrapers of course is not feasible in the long term.
One of the best ways to monitor scrapers is by using a web scraping monitoring service. These services allow you to monitor all of your scrapers from a single dashboard, providing real-time updates on their status, performance, and errors. Some monitoring services also provide alerts and notifications, so you can quickly address any issues that arise.
Scrapy Cloud by Zyte
One of the most known monitoring web interfaces is Scrapy Cloud by Zyte, where you can schedule your scraper and monitor their executions, and it integrates naturally with Scrapy (also because Scrapy is maintained by Zyte itself)
Scheduling Process and Tools for Scrapy Spiders
The scheduling process is another challenge that comes with large web scraping projects. Scheduling involves determining the frequency of scraping, setting the start and end times of the scraping process, and managing the execution of multiple scrapers simultaneously. This process can become overwhelming when dealing with hundreds of scrapers, especially if they have different schedules and requirements.
Besides Scrapy Cloud, which we already covered before, other solutions include Scrapyd and Cron (or Task Scheduler if you’re working on Windows)
Scrapyd
Fortunately, there are tools available to help you manage the scheduling process for Scrapy spiders. One such tool is Scrapyd. Scrapyd is a web service that allows you to schedule and run your Scrapy spiders from a remote server. With Scrapyd, you can manage the scheduling of your spiders from a single dashboard, regardless of where they are running. We have seen how it works in another THE LAB post
Cron / Task Scheduler
Another great option for running your Scrapy spiders is using the OS task scheduler of your servers. It’s more of a manual approach and can be challenging for hundreds of scrapers but, in my experience, can be done in a smart way by integrating a database where the scheduling parameters are stored and used by Cron.
Scrapeops, for both scheduling and monitoring
What is Scrapeops?
Looking for a monitoring tool for my Scrapy spider fleet I’ve noticed Scrapeops (good job with the SEO guys :) ).
Actually, they have two solutions on their website: a proxy aggregator, a sort of API on top of the major proxies API, that makes Scrapeops the one-stop shop for IP rotation.
The other solution is their monitoring and scheduling dashboard for scrapers, and that’s the product we’re seeing today.
Scheduling with Scrapeops and scrapyd
We have already seen in a previous post how to set up a scrapyd server and connect it to Scrapeops.
We will focus more now on how to set up a scraper for monitoring on Scrapeops dashboard.
Monitoring your scrapers with Scrapeops
Integrating Scrapeops in your python scrapers, made both with Scrapy or requests.
Integrating Scrapeops with your Scrapy spiders
First of all, you need to install the needed python package
<code>pip install scrapeops-scrapy</code>
Then, after you’ve created a free account on Scrapeops’ website, you will receive an API key you can see in the account settings.
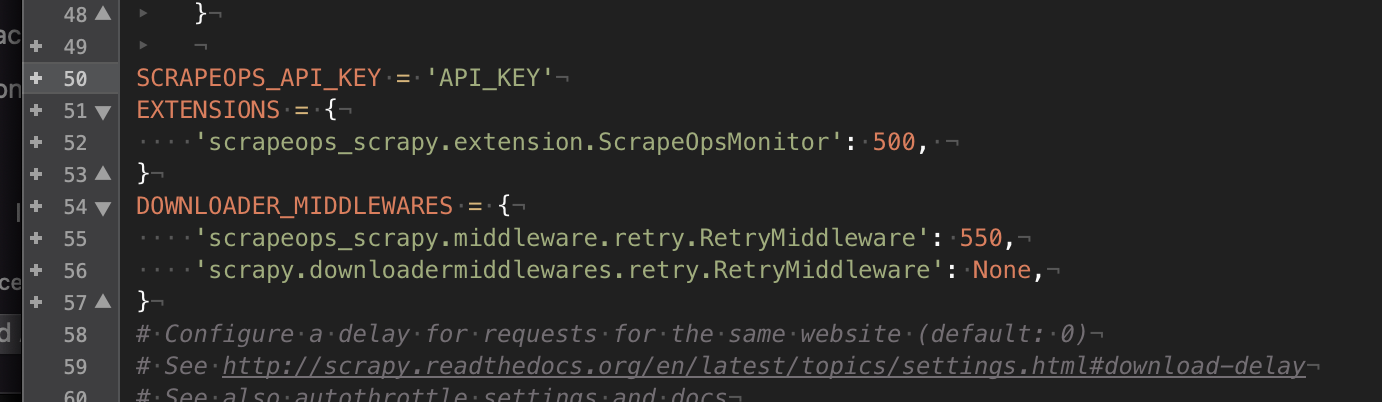
The last step is to add the settings to the scrapers, as follows:
[

{kind=link}
Scrapy settings
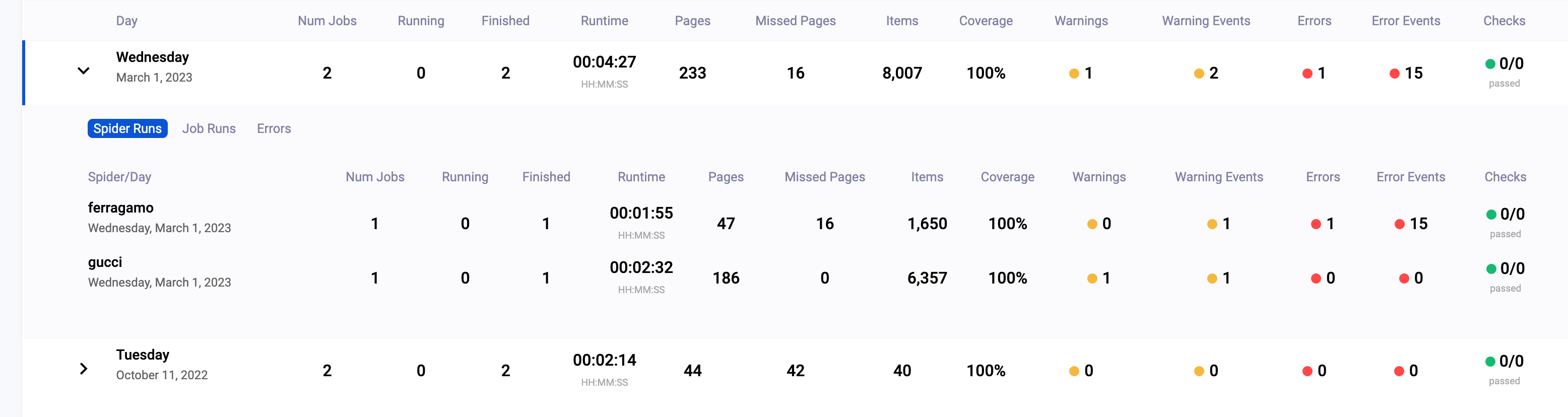
After running the scraper you will see in the Scrapeops dashboard your executions.
[

{kind=link}
Scrapeops dashboard
Integrating Scrapeops in your python requests scrapers
Even in this case, as a first step, you need to install the proper package.
pip install scrapeops-python-requests
Now let’s create a python script that, given some products’ pages, returns their name and logs everything on the Scrapeops dashboard.
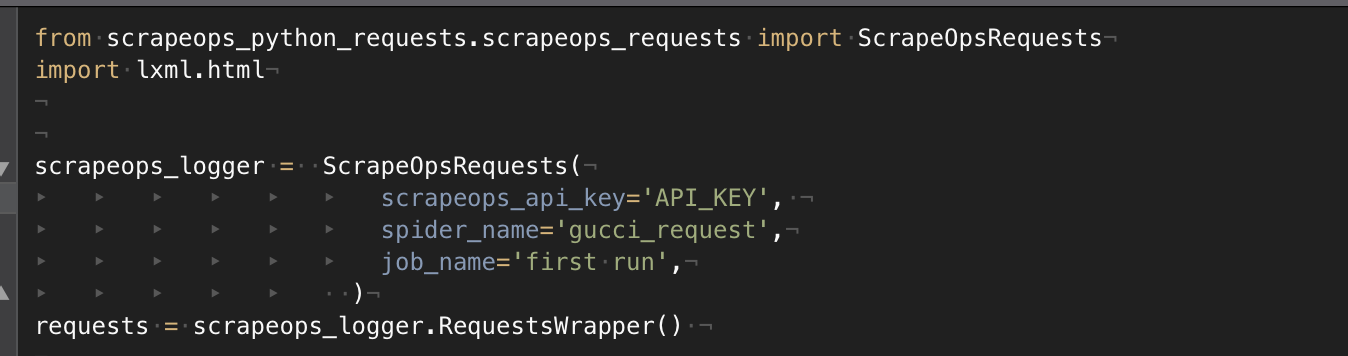
We need to import the package we’ve just installed, initialize the variables needed, and the python request wrapper.
[

{kind=link}
python-requests initializing
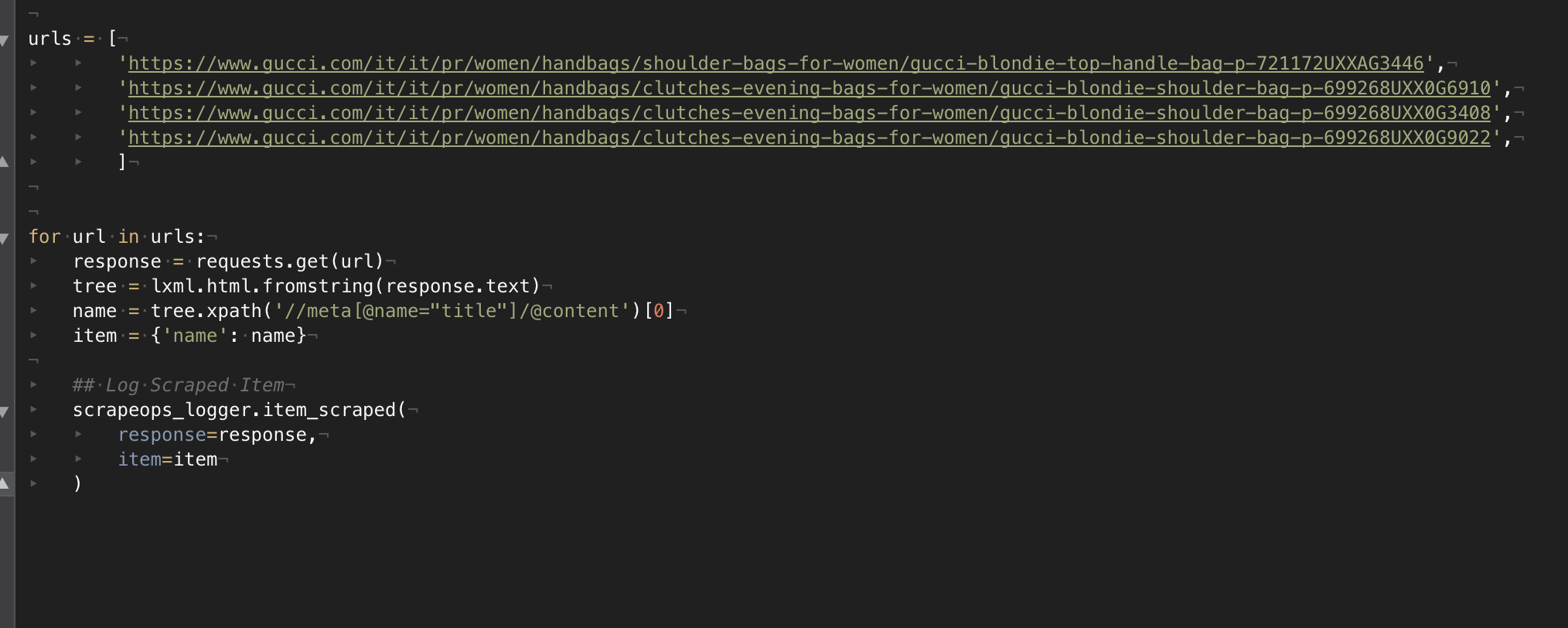
Then we create the simple test spider for getting the titles from the meta tag of the product pages.
[

{kind=link}
python-requests scraper
That’s it! If we run the scraper, we can see the execution on the monitor of Scrapeops.
[

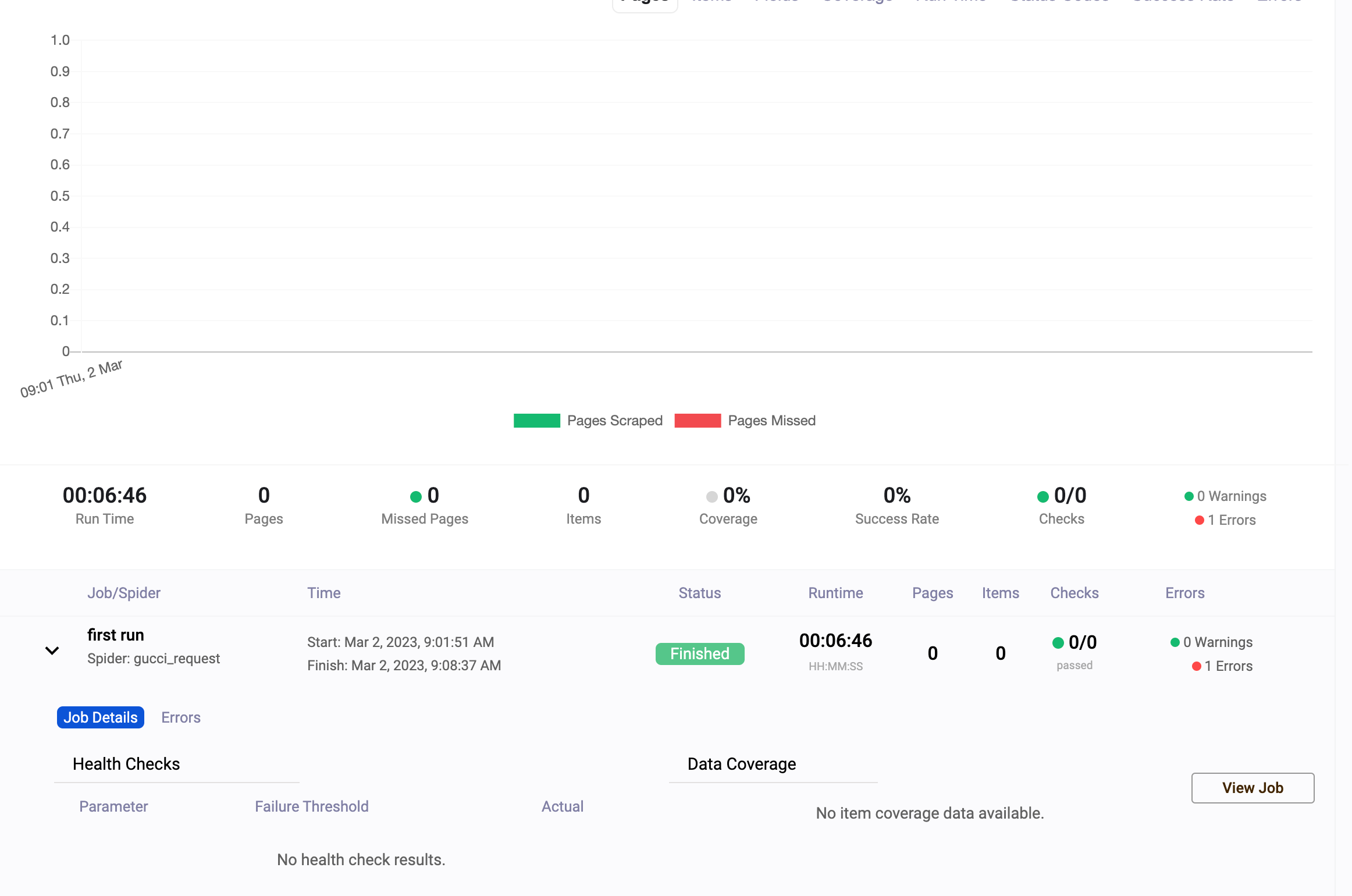{kind=link}
Dashboard first run with requests
Bonus content:
The monitoring works but the spider has some issues. Probably the target website blocks python-requests and we need a real browser fingerprint.
To bypass this block we can pass directly some fixed headers in the script or we can decide to use the Scrapeops fake browser headers API. Basically, it’s an API call that returns a list of plausible browser headers, from which we can pick a random one to use in every request we make.
The implementation is quite basic and you can see the full code on the GitHub repository.
As a result of this integration, the spider now works perfectly as we can see from the console.
[

{kind=link}
Dashboard with requests and random headers
Unluckily at the moment, it’s possible to integrate with the dashboard only scrapy and requests scraper, making this solution incomplete for any large web scraping project, since usually there are more solutions involved (Playwright, Selenium, Puppeteer). From their website, you can register interest in these integrations and if they will be implemented Scrapeops dashboard will become a must-have for most of us.
That’s it! I hope you’ve found this article useful, please write any feedback here in the comment section or via mail at pier@thewebscraping.club.