This article is sponsored by MobileHop, your mobile IP proxy provider.
[

{kind=link}
MobileHop provides native mobile IPs on dedicated 4G/5G modems via Verizon and AT&T Wireless to bypass almost all website blocks. A single multihop license gives you access to 50 USA markets and growing!
One more self-promotion announcement: thank you to anyone who yesterday followed the Zyte webinar about data quality in web scraping, where I was participating as a guest. You can still see it on demand via the Zyte webinar portal.
In the latest post, we have seen how to scrape a Kasada-protected website, using both free and commercial tools.
Many of you found it useful for their projects, despite Kasada seeming to have a relatively small market share in the business.
Since it’s been a while since I’ve written about Cloudflare solutions and things do evolve rapidly in this industry, I’ve decided to update my old article about scraping Cloudflare-protected websites, using the same format as the Kasada one but with a difference. We’ll test the solutions both on a local environment and on a remote virtual machine on AWS. This is because the website we’re going to analyze has Cloudflare activated probably at the highest levels of paranoia and you can’t even browse it from there.
[

{kind=link}
Browsing Harrods’s website from VM in AWS
What is Cloudflare and how it works?
Cloudflare is a global technology company that provides a variety of services to enhance the performance, security, and reliability of websites and internet applications. The company operates a vast network of data centers worldwide, which allows it to offer content delivery, DDoS protection, and other services to its clients. Cloudflare’s solutions are designed to optimize website performance, reduce latency, and safeguard websites from various online threats, including cyberattacks and malicious bots.
Cloudflare Bot Management is a specific solution provided by Cloudflare that aims to identify and control the activities of automated bots on a website or application.
This solution employs machine learning and behavioral analysis to differentiate between legitimate and malicious bots. By analyzing traffic patterns, request rates, and other factors, it can accurately identify and block harmful bots in real-time, while allowing legitimate bots to access the site.
Some key features of Cloudflare Bot Management include:
-
Advanced bot detection: By using machine learning algorithms and heuristics, Cloudflare can identify and block a wide range of malicious bots, including those that may be using sophisticated evasion techniques.
-
Customizable rules: Cloudflare allows users to create custom rules to manage bots according to their specific needs, enabling them to fine-tune the level of protection and control.
-
Real-time analytics: Cloudflare provides users with real-time insights into bot traffic, allowing them to monitor and analyze bot activity on their website or application.
-
Integration with other Cloudflare services: The bot management solution can be easily integrated with other Cloudflare offerings, such as the Web Application Firewall (WAF) and rate limiting, to provide comprehensive protection against various online threats.
One of the major issues when tackling Cloudflare is its customization of the rules. Some scraper might work for one website but not for another one. For this test, I’ve chosen one of the toughest websites that recently increased its anti-bot restrictions level to the highest possible.
Free solutions
Playwright with Chrome
I’ve used the same setup we have seen in the Kasada post and, when run locally, the solution allows me to open the home page.
[
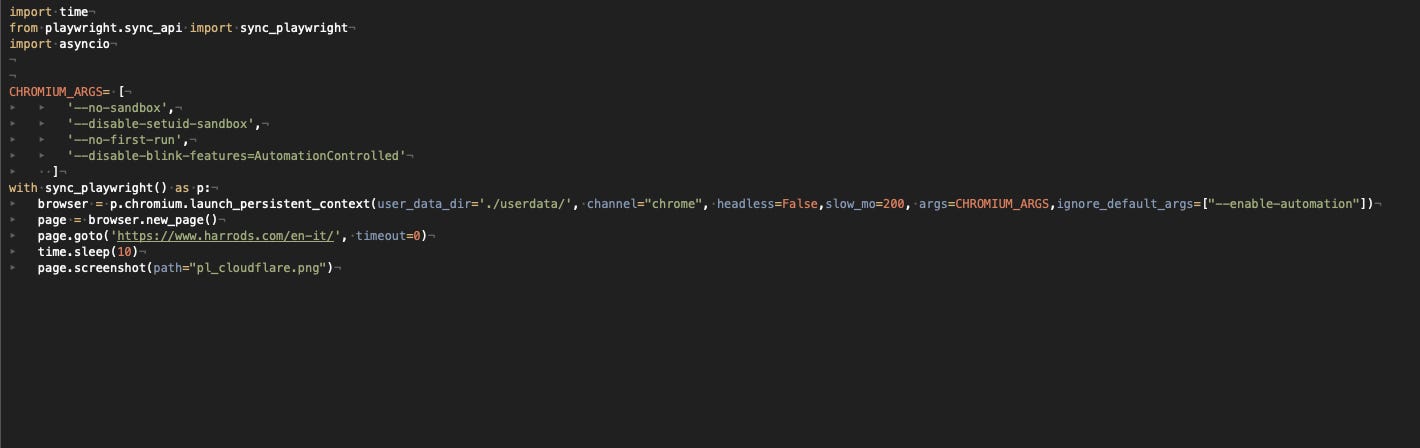
{kind=link}
Playwright with Chrome test
While running on a VM on AWS, we still get blocked on the first try with a challenge
[

{kind=link}
Harrods Cloudflare Challenge
Playwright with Firefox
Let’s try then Playwright with Firefox, first on the local environment and then on AWS VM.
[

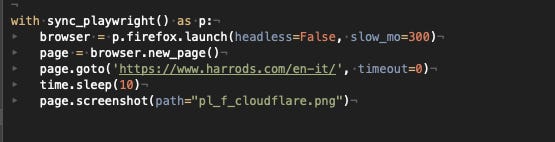{kind=link}
Playwright with Firefox code
Again, we got the same results as the Chrome try. On the local environment works like a charm, but from the AWS VM, it requires bypassing the challenge.
Undetected Chromedriver
Let’s try then with the Undetected Chromedriver again in both environments.
[

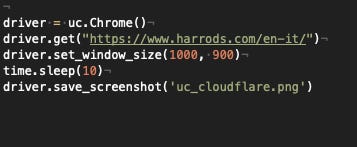{kind=link}
Undetected Chromedriver code
Local setup works, while on AWS again the same result, we need to bypass a challenge to scrape the website.
Without any surprise, also a test with Pyppeteer had the same results.
Final thoughts on the free solutions
If your target, like mine, is to run a large number of scrapers in an automatic and cheap way, this situation poses several challenges. I’ve tried to run these scrapers on AWS, but from GPC and with proxies from both of them the results are the same. And we cannot rely on home computers for our large-scale web scraping projects. So I needed to expand my research for a solution to commercial ones, and this is exactly what I meant when, some months ago, I wrote that the costs of web scrapers are getting higher. But if you have any solution, I’d ve glad to hear them on our Discord Server or via mail at pier@thewebscraping.club
Commercial solutions
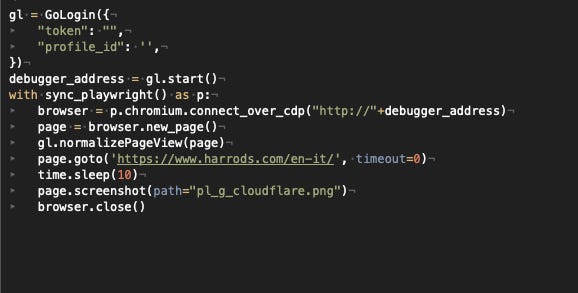
Playwright with GoLogin
Instead of opening a Chrome or Firefox browser, we can use GoLogin’s browser and its multiple profiles offered to bypass Cloudflare.
In this case, we’re going to attach the Playwright script to an open GoLogin instance but the result is the same. OK on a local machine but not good on VM.
[

{kind=link}
Playwright with GoLogin
Bright Data Web Unblocker
This last solution is finally the one that works great both locally and from VMs.
I’ve attached the scrapy spider in the GitHub repository of The Lab but, as we already have seen in the first “Hands On” issue, it’s the only solution that doesn’t require us to manage a headful browser.
As we have seen in its product review, the Bright Data Web Unblocker is a proxy API we can integrate into our Scrapy projects (or any other tool), and it automatically handles all the settings and features needed to bypass the Cloudflare challenge.
Final remarks
This is the first case in my entire career as a web scraper that I could not avoid using a commercial solution for bypassing an anti-bot software. Frankly speaking, this annoys me, because it keeps pushing the costs of web scraping higher and higher. On the other side, the UX on Harrods’ website is awful. Accessing via a VPN or from other devices that are not recognized as ‘good ones’ by the software makes the experience of browsing the website a nightmare.
Probably, since the solutions are working locally but not from the VMs, the solution could be to add more noise in the device fingerprint with some options or addons in Chrome or other tools, I’ll keep studying it.