This post is sponsored by Proxyempire, your trusted proxy partner. Sponsorships help keep The Web Scraping Club Free and it’s a way to give back to the readers some value.
[

{kind=link}
In this case, for all The Web Scraping Club Readers, using the discount code TWSC10 you can save 10% OFF for every purchase.
Share this post on Hacker News
Let’s continue our journey on the tackle of antibot systems. Today, after seeing Kasada and Cloudflare, it’s the turn of Datadome.
As always, please read carefully the following disclaimer: all the information you will find here are for research purpose and should not be used to cause damage to any website business or operations. Scrape carefully and ethically without disturbing the operativity of the target website and only publicly available data not protected by copyright.
What is Datadome and how it works?
Datadome Bot Protection is a comprehensive software solution that is designed to protect your website or application from various types of malicious bots. The solution uses advanced bot detection techniques, such as device fingerprinting, behavior analysis, and machine learning algorithms, to distinguish between human and bot traffic. By identifying and blocking malicious bots, Datadome helps improve website performance, protect sensitive data, and prevent fraud.
One of the key features of Datadome is its ability to detect and block automated attacks that can cause harm to your website or application. These automated attacks can come in many forms, including scraping, account takeover, credential stuffing, and more. Datadome uses a variety of techniques to detect and block these attacks, including analyzing user behavior and patterns, analyzing IP addresses and user agents, and analyzing traffic patterns.
Datadome also includes a real-time dashboard that allows you to monitor bot activity and take action if necessary. This dashboard provides a detailed view of bot traffic, including the number of bots detected, the types of bots detected, and the actions that were taken. You can also set up alerts to notify you when certain bot activity is detected, allowing you to take immediate action to protect your website or application.
Overall, Datadome Bot Protection is a powerful solution that can help protect your website or application from the growing threat of malicious bots. By using advanced bot detection techniques and providing real-time monitoring and alerts, Datadome can help improve website performance, protect sensitive data, and prevent fraud.
How to detect Datadome?
The easiest way is via tools like Wappalyzer that test the tech stack of a website and can detect which anti-bot is used on it.
[

{kind=link}
Datadome protected website
Another way is to inspect the cookies of the requests made to the target website: as an example, when we browse to Footlocker.it, as a response to the first request we get a Datadome cookie.
[

{kind=link}
Datadome Cookie
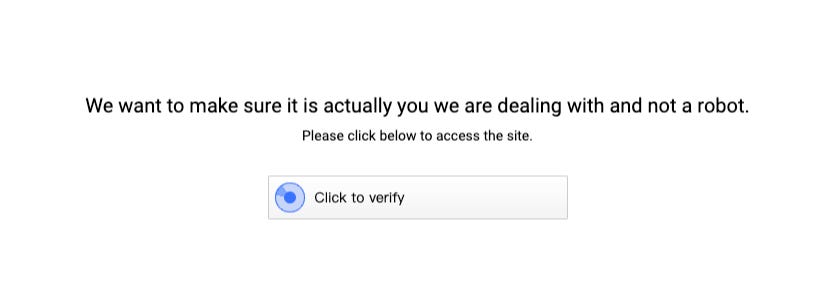
When browsing also a Datadome-protected website in Incognito mode, especially if it’s the first time you’re visiting it, you can encounter one of their challenge with a slider.
[

{kind=link}
Datadome Captcha
Free solutions
Given that results may vary from the target website configuration and from the environment you’re running the tests from, let’s try to figure out how to bypass Datadome Bot Protection first with some free open-source tools.
Given that a basic scraper with Scrapy, with no Javascript rendering, has 0 chance to bypass it, let’s test some solutions with headful browsers.
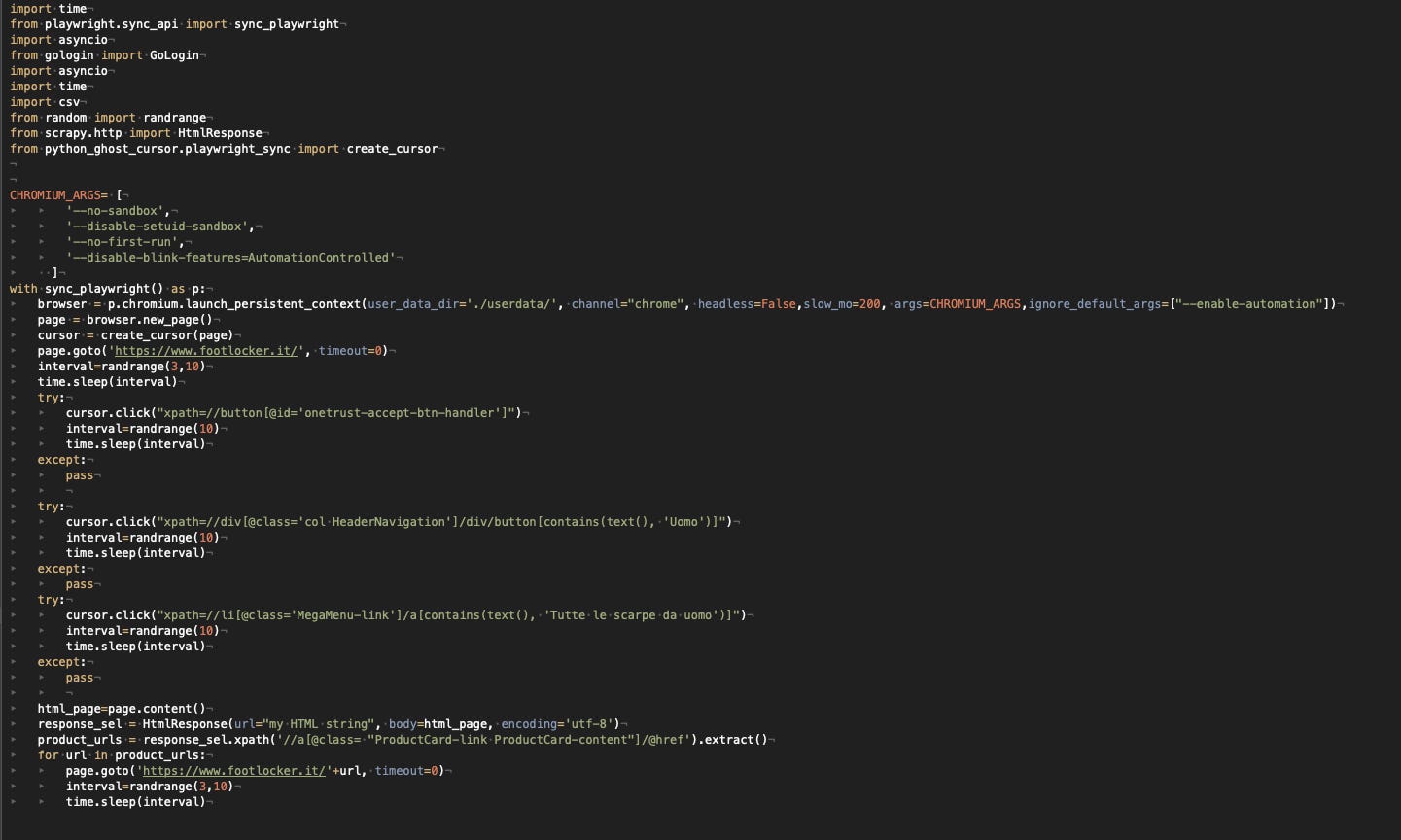
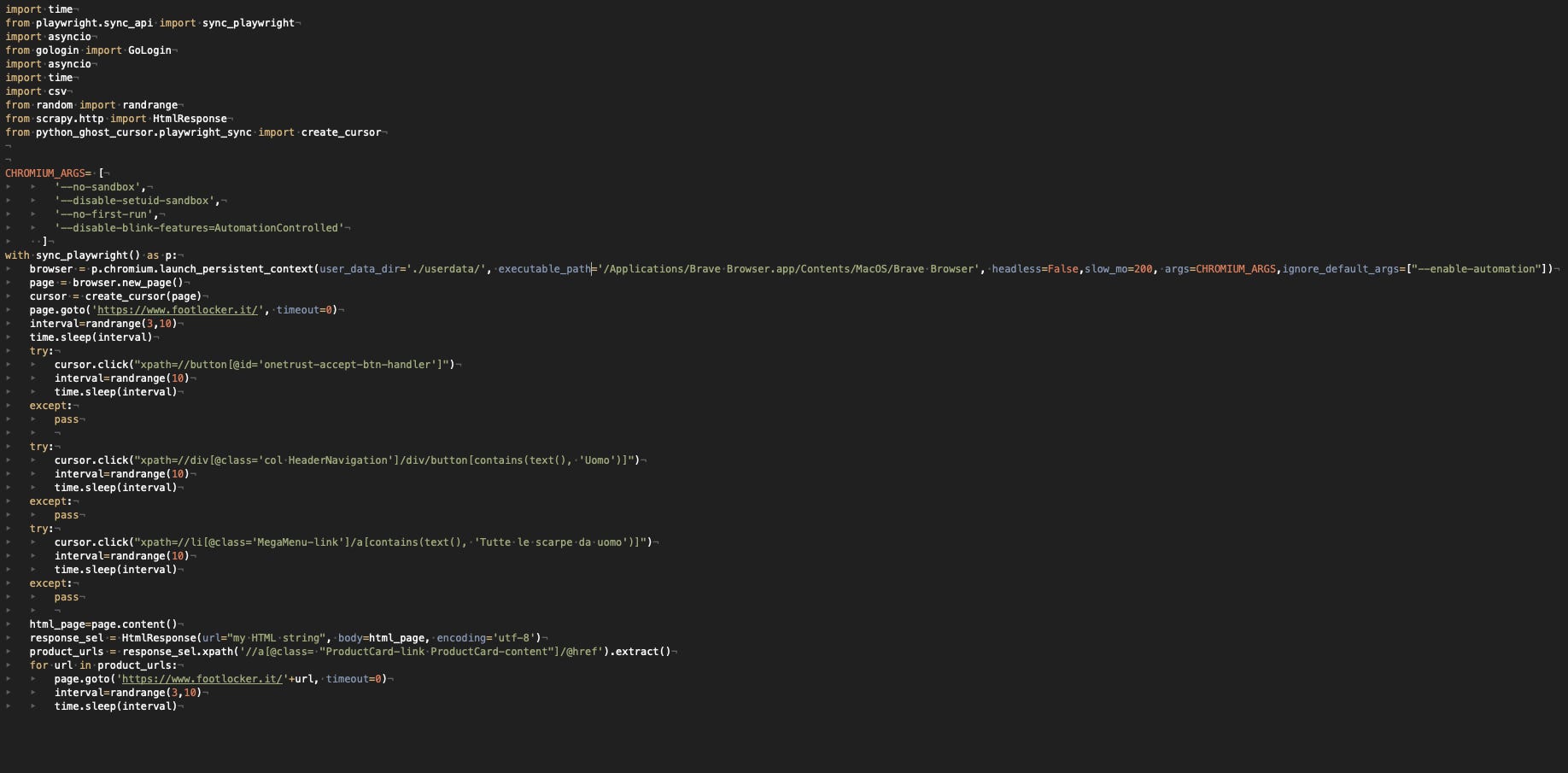
Playwright with Chrome ❌
We start our tests on a local machine with Playwright and Chrome. I’ve added to the standard configuration a new package I’ve discovered, python_ghost_cursor, which simulates human mouse movements using Bezier curves, which we have seen in our old post.
[

{kind=link}
Scraper with Playwright and Chrome
Anyway, this didn’t help since I’ve got the captcha when I try to go to the product list page of men’s shoes.
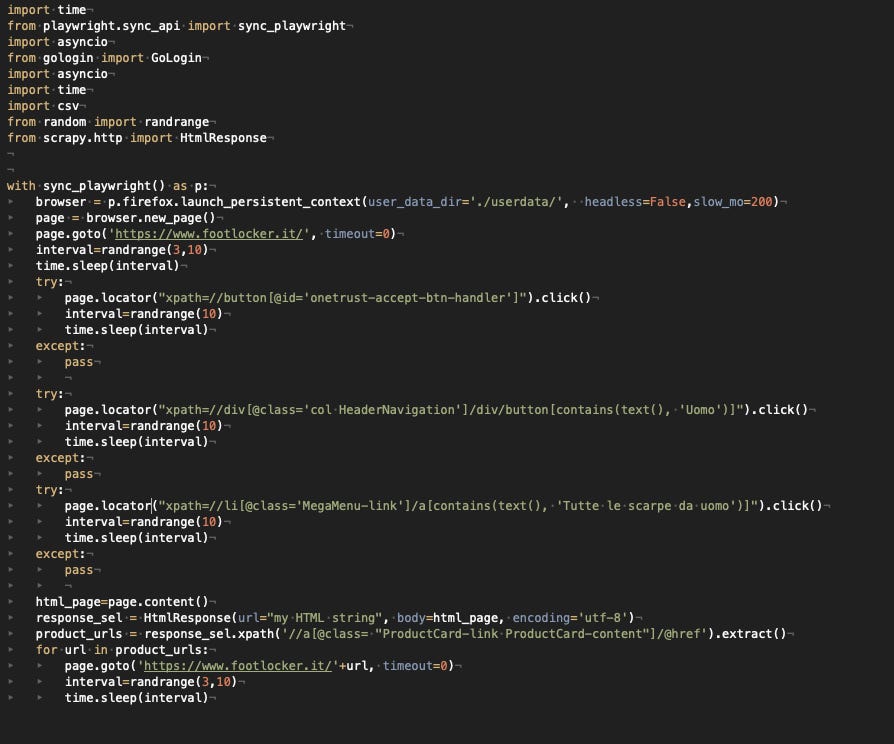
Playwright with Firefox ✅
Things got better after switching to Firefox, even if I needed to delete the python_ghost_cursor package since it works only with Chrome.
[

{kind=link}
Scraper with Playwright and Firefox
The results from both a local environment and a VM on a datacenter are great, so this solution is definitely approved. It seems that Chrome leaks some data used by Datadome to understand if there’s automation behind its execution. Let’s give it another try with another Chromium-based browser like Brave.
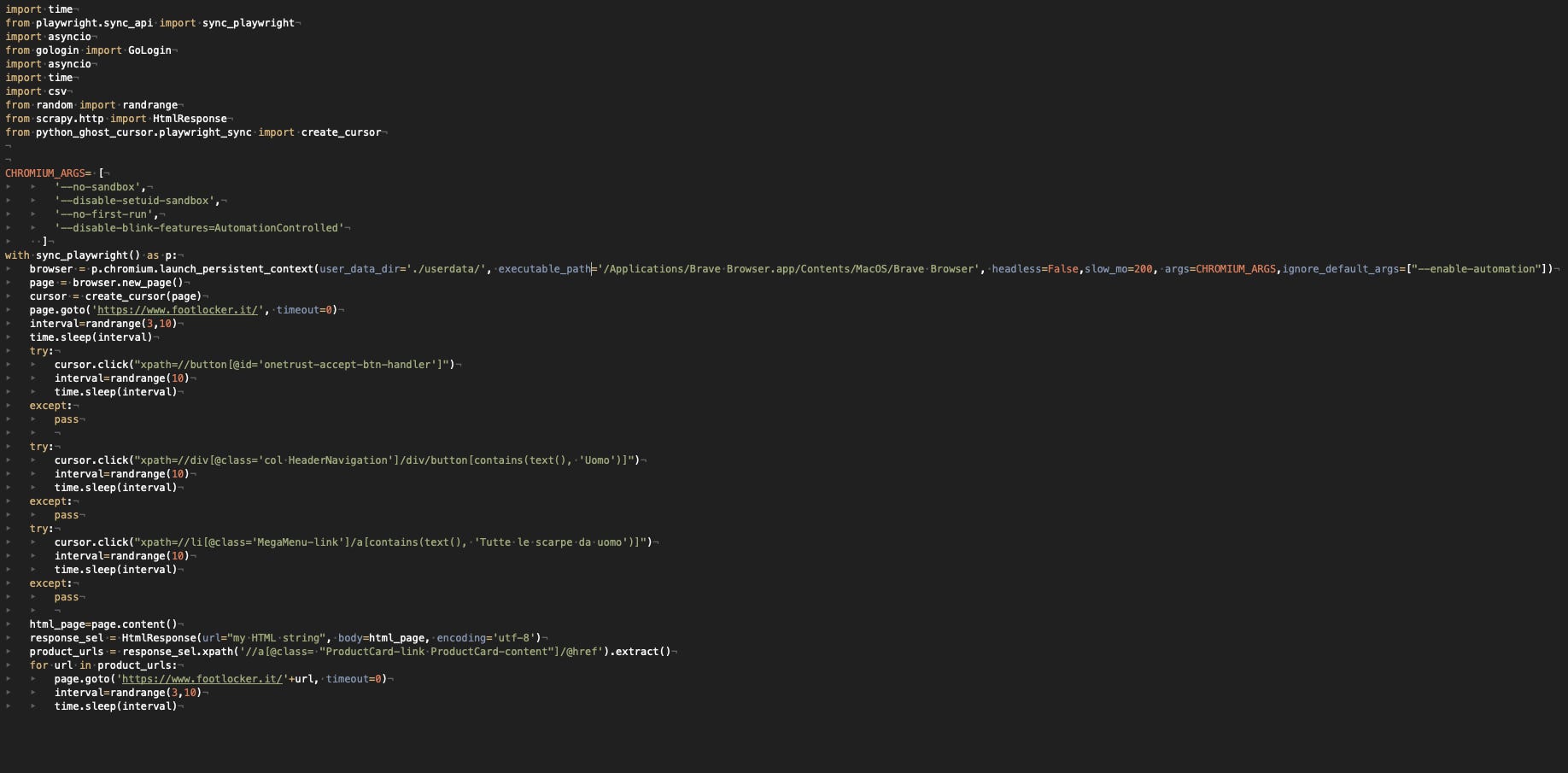
Playwright with Brave ✅
I’ll use the same scraper we’ve seen before with Chrome but change the executable path of the browser to point to Brave browser.
[

{kind=link}
Scraper with Playwright and Brave
I’m able to browse the website both on a local machine and on a VM so it seems that the data leak depends strictly on Chrome. Good to know, now we have more free options to use.
Final thoughts on the free solutions
Datadome is gaining popularity as an anti-bot solution and bypassing it has a cost, especially if you need several large websites in your projects. As we have seen, we need headful browsers, so it means more CPU and memory to allocate for the scraper execution, but, at least, it can be bypassed with free tools.
On the other hand, we have some commercial solutions that allow us to bypass Datadome using a simple Scrapy spider and an API. These API calls have a cost but we can reduce significantly the execution costs for the machines hosting our scrapers. The convenience of these solutions depends from case to case but they are worth noting.
Commercial solutions
Bright Data Web Unlocker ✅
As we have seen on the first episode of the “Hands On” series, the Bright Data Web Unlocker fits great against Datadome. I’ve included in the GitHub repository the test we’ve made but with a simple Scrapy spider and a call to a proxy, we can get the data we want without worries. If you want to test the Bright Data Web Unlocker, you can subscribe here for a demo.
Zyte API ✅
The same can be said for the Zyte API. In this case, we need to specify that we’ll use a browser rendering to extract data correctly but after doing it, I’ve not encountered any issues. If you’re willing to try the Zyte API by yourself, you can claim $25 free credit following this link.
[

{kind=link}
Scraper with Zyte Api
Final remarks
With the sophistication of the anti-bot software, the technology stack needed to bypass it is getting more and more expensive, and it could only get worse.
These days I find myself thinking about how to rationalize the web scraping pipeline in my company. Should we keep using more and more headful browsers, which are free but unreliable when they need to be up and running for some hours? Or we should cross the line and go pay for commercial tools? My spreadsheets are on fire since I’m making some math to understand the costs of both scenarios.
Do you have similar experiences? Please write me at pier@thewebscraping.club.
The Lab - premium content with real-world cases
-
THE LAB #14: Scraping Cloudflare Protected Websites (early 2023 version)
-
THE LAB #8: Using Bezier curves for human-like mouse movements
-
THE LAB #6: Changing Ciphers in Scrapy to avoid bans by TLS Fingerprinting
-
THE LAB #4: Scrapyd - how to manage and schedule a fleet of scrapers
-
THE LAB #2: scraping data from a website with Datadome and xsrf tokens