Bypassing Perimeterx in 2023 with code and examples
Excerpt
How to bypass PerimeterX anti-bot solution using both free and commercial solutions in 2023, with practical examples and code
This post is sponsored by Oxylabs, your premium proxy provider. Sponsorships help keep The Web Scraping Free and it’s a way to give back to the readers some value.
In this case, for all The Web Scraping Club Readers, you can get a discount of 35% off Residential, Mobile proxies, Web Unblocker, and Scraper APIs’ regular plans by following this link.
PerimeterX anti-bot solution, recently acquired by Human, is one of the most spread anti-bot solutions on the web.
As with every modern anti-bot solution, it uses all the most recent techniques to detect bot traffic and scrapers like:
-
fingerprinting on different layers
-
IP filtering
-
AI applied to behavioral analysis
In this post we’ll see some techniques, both free and commercial, to bypass a PerimeterX-protected website like Neimanmarcus.com.
These techniques and the code on our GitHub repository (available for paying readers), should be taken as a starting point since each website could implement its protection in different ways.
If you’re a paying user and don’t have access to the GitHub repository, write me at pier@thewebscraping.club, since I need to give you access manually**.**
How to detect if a website uses PerimeterX?
You can use the free Wappalyzer Chrome extension and, in the security section, if a website uses PerimeterX you should see it.
[

{kind=link}
Wappalyzer detected PerimeterX
If you don’t want to, or you’re unable to use Wappalyzer, you can check the stored cookies of a website and look for one called pxhd, like the following:
Set-Cookie:
_pxhd=mepSfyVT0voiGSF9HsgdW4GlbT9YEefstfxozu2ajYq03dJV8h2lkYZyeOKOzoI85m8SLs/5HvDHR7cL3xekUQ==:q54rImD/eeV8qJLNcp3bRbS70bTuuAPgMys0dty8tiWi4DfdxA1bKCqbaFXUNhNIaW3etC3KxGcSDewg7TBKJDu7lhV1MegAxcolO-AJEAE=; Expires=Wed, 14 Aug 2024 16:52:01 GMT; path=/;
One of the distinctive trait of the bot protection is the “Press and Hold” button, which looks like the following.
[

{kind=link}
PerimeterX Press and Hold Captcha
Free solutions
Undetected Chromedriver
We’ve recently reviewed the Undetected Chromedriver version 3.5 and we’ve found out that it performs quite well with PerimeterX, both in a local environment and on a datacenter, using the proper proxies to avoid bans in IP ranges and IP rate limit.
In the GitHub repository, inside the file undetected-chromedriver.py, you’ll find out a scraper that crawls one item category, using undetected-chromedriver.
You will notice a peculiarity: I’ve used Brave Browser instead of Chrome, and this is because after loading the first page, UC gets stuck on a call to an external API. This doesn’t happen when using Brave Browser.
options = uc.ChromeOptions()
options.binary_location = '/Applications/Brave Browser.app/Contents/MacOS/Brave Browser'
driver = uc.Chrome(headless=False,use_subprocess=True, options=options)
driver.get("https://www.neimanmarcus.com/")
Playwright
One of the reasons I prefer Playwright to other tools like Selenium is its ductility: with few changes we can test different configurations and browsers without rewriting a scraper.
The first working solution we’re seeing could be also implemented by using Plawright + Firefox, again eventually with a proxy provider when executed on a datacenter.
This works basically straight out of the box, with only one additional option: when running the scraper from a server connected with a low latency network is slow_mo. It artificially slows down the execution of Playwright and I suppose this tricks the anti-bot, simulating a slower connection.
with sync_playwright() as p:
browser = p.firefox.launch(headless=False, slow_mo=300)
page = browser.new_page()
page.goto('https://www.google.it', timeout=0)
interval=randrange(10)
time.sleep(interval)
page.goto('https://www.neimanmarcus.com', timeout=0)
page.wait_for_load_state("load")
You can find the full scraper in the repository, inside the file playwright_firefox.py.
Things are not so smooth instead when using the Chromium browser. It loads the website’s main page but then we got blocked on the first product page.
To make Chrome work against PerimeterX, we need to modify the scraper as follows:
CHROMIUM_ARGS= [
'--no-sandbox',
'--disable-setuid-sandbox',
'--no-first-run',
'--disable-blink-features=AutomationControlled'
]
....
with sync_playwright() as p:
browser = p.chromium.launch_persistent_context(user_data_dir='./userdata/', headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"])
page = browser.new_page()
page.goto('https://www.google.it', timeout=0)
interval=randrange(10)
time.sleep(interval)
page.goto('https://www.neimanmarcus.com', timeout=0)
We’re disabling via command line the Google Sandbox, the first run page and the infobar saying that the browser it controlled by an automation.
On top, we’re using a Chrome installation and not a Chromium one, with a persistent context.
With this setup, contained in the file playwright_chrome.py, we can crawl the whole product category.
More or less, the same configuration can be applied to Brave browser. We’ll explicitly set the executable path for Brave and leave only the compatible options as arguments.
CHROMIUM_ARGS= [
'--no-first-run',
'--disable-blink-features=AutomationControlled'
]
.....
with sync_playwright() as p:
browser = p.chromium.launch_persistent_context(user_data_dir='./userdata/', executable_path='/Applications/Brave Browser.app/Contents/MacOS/Brave Browser', headless=False,slow_mo=200, args=CHROMIUM_ARGS,ignore_default_args=["--enable-automation"])
page = browser.new_page()
page.goto('https://www.google.it', timeout=0)
interval=randrange(10)
time.sleep(interval)
page.goto('https://www.neimanmarcus.com', timeout=0)
Final thoughts on free solutions
We’ve seen several approaches to bypass PerimeterX: as mentioned at the beginning of the article, they could be used as a starting point in your projects, since results may vary from the target website and the scraper running environment. Since PerimeterX uses also behavioral analysis to detect bots, you may have noticed I’ve introduced random sleeps from one action to another and also some random mouse scrolling.
Maybe not the most advanced solution but it seems enough to confuse the AI model for bot detection and have a green flag.
Commercial solutions
Depending on the scope and the frequency needed for your extractions, adopting these free solutions could be painful for your budget. You need an infrastructure which supports an headful version of the scraper and a fully working browser operating for some hours, with multiple occurrences of the scraper.
Doing some math, depending from the efficiency of your scraping infrastructure, you could consider using a commercial solution like the Oxylabs Web Unblocker we’ve recently reviewed or others.
To get an idea of how they work and what’s more suitable for your target website, you can have a look at our Hands On series, where we test all these kind of tools.
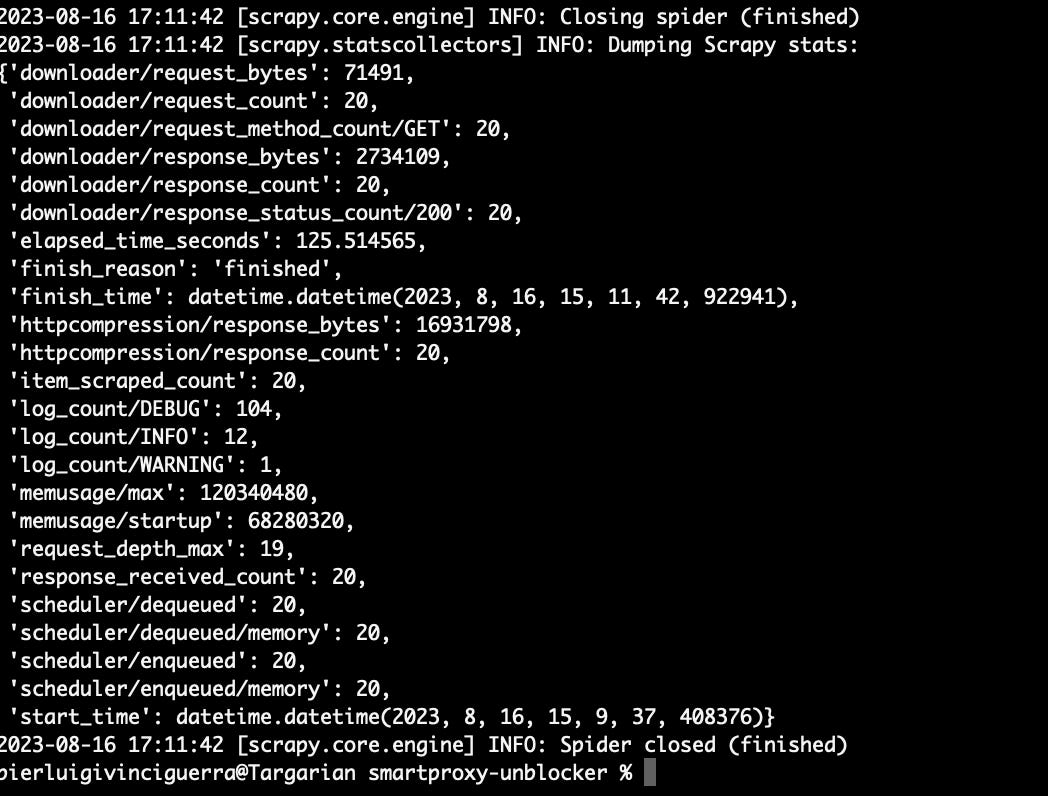
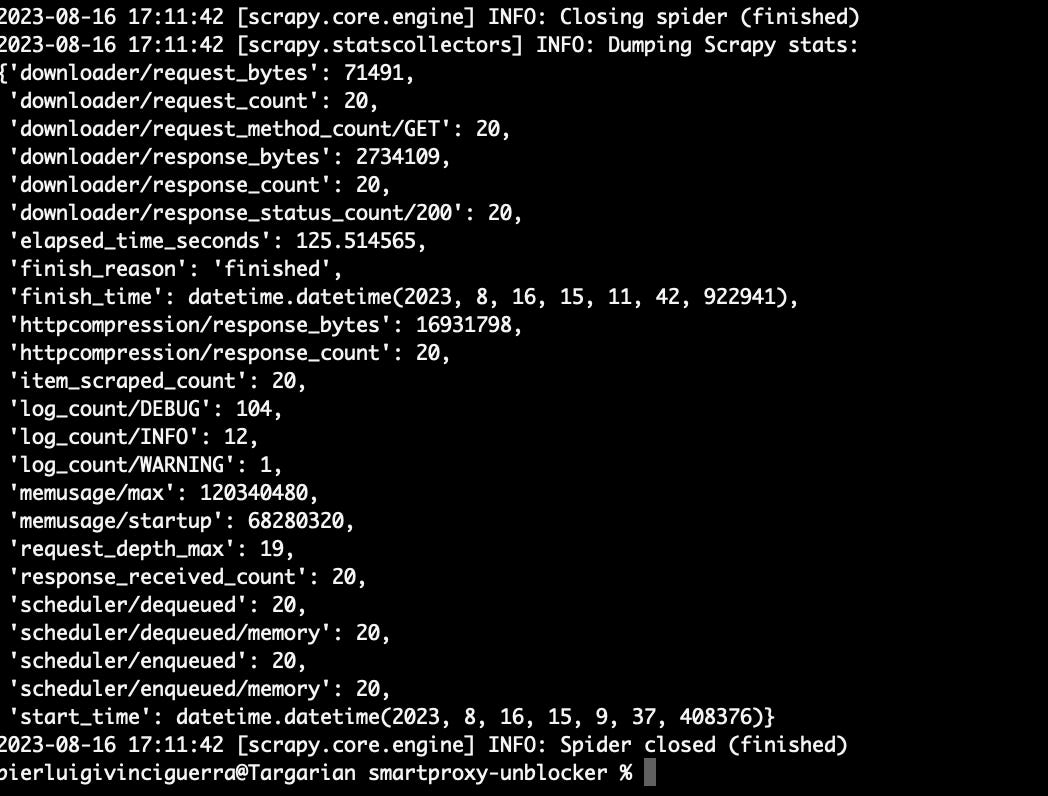
To have an idea on how much it will cost a full run on Neiman Marcus website, I’ve made a test.
[
{kind=link}
I’ve requested 20 URLs of product list pages and the responses weighted 17MB (httpcompression/response_bytes). It means that every page product list page like this one consumes 0.85MB of bandwidth.
Considering that every product list page contains 120 items when complete and the whole website has around 50k items, it means that in the most efficient case we’ll need 416 requests to scrape all the items in the website.
Let’s suppose we make 500 requests for the whole website and the total bandwidth we’re going to pay would be 425MB.
Considering the price of 15 USD per GB on the smallest plan of the Oxylabs Web Unblocker (and you can still have a 35% discount following this link), a single run would cost you approx 6 USD (or 4 if you get the discount).
If your infrastructure is more efficient and your extraction costs are below this threshold, good for you! If not, I would consider this option.
And in case your target website exposes API protected with anti-bot, the costs are even lower, since you’ll use much less bandwidth.
Also this code can be found on the GitHub repository available for paying subscribers, if you’re one of them and don’t have access to it, please write me at pier@thewebscraping.club to get the permission.