Bypassing Datadome with Web Scraping - End of 2023 Version
Excerpt
Is it possible to scrape a Datadome-protected website today? With enough time and resources probably yes. Let’s see together a practical example with code
Before starting with the main topic of the article, where I’ll try some approaches to scrape data from a Datadome-protected website, let me remind you of a webinar by Smartproxy, coming out in the next few hours. I’ll be there with
, Martin and Ivan talking about efficiency in web scraping operations.
[

Here’s the link to save your seat for free, hope to see you there in a few hours from now.
An Intro to Datadome Bot Protection
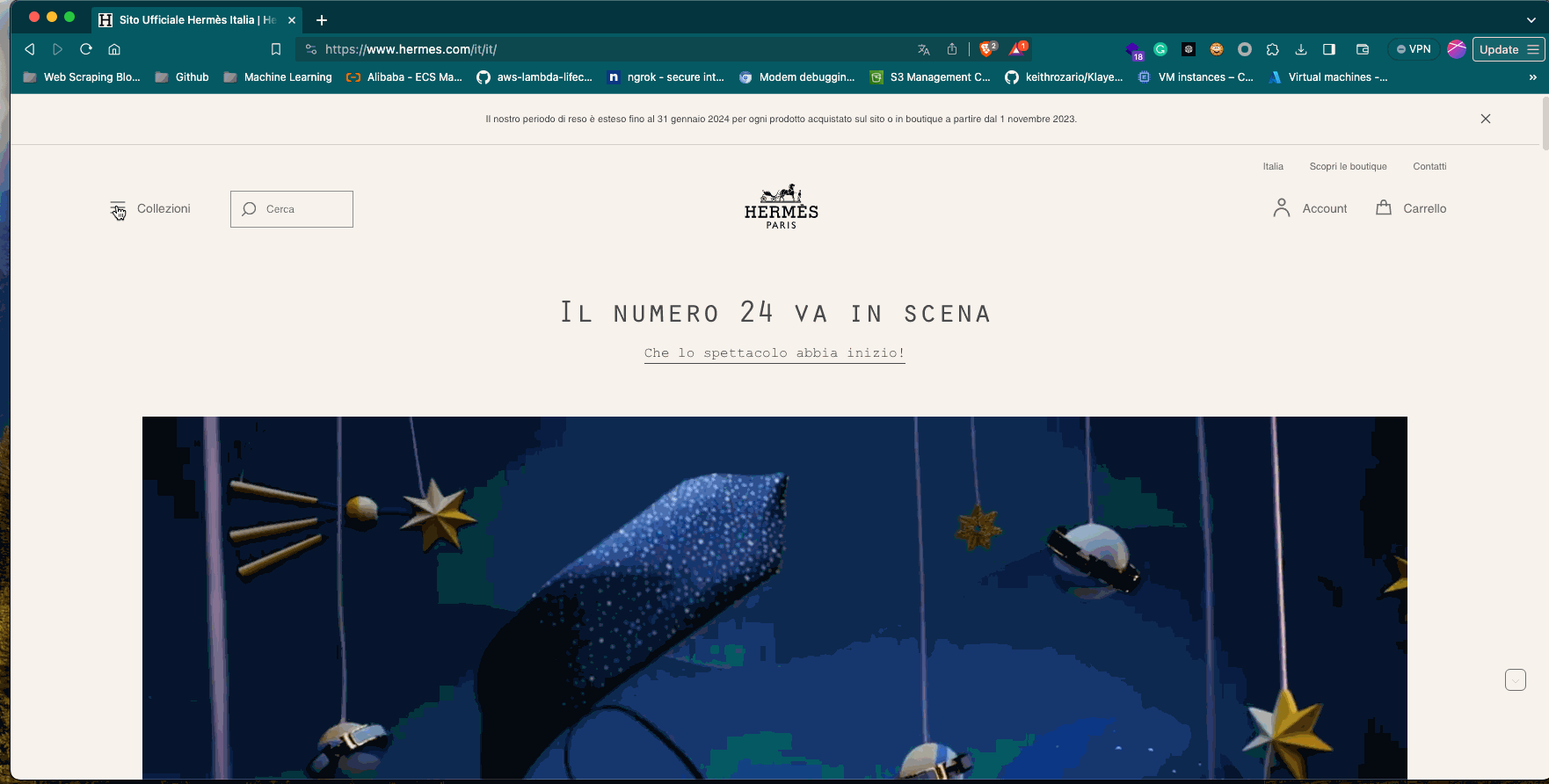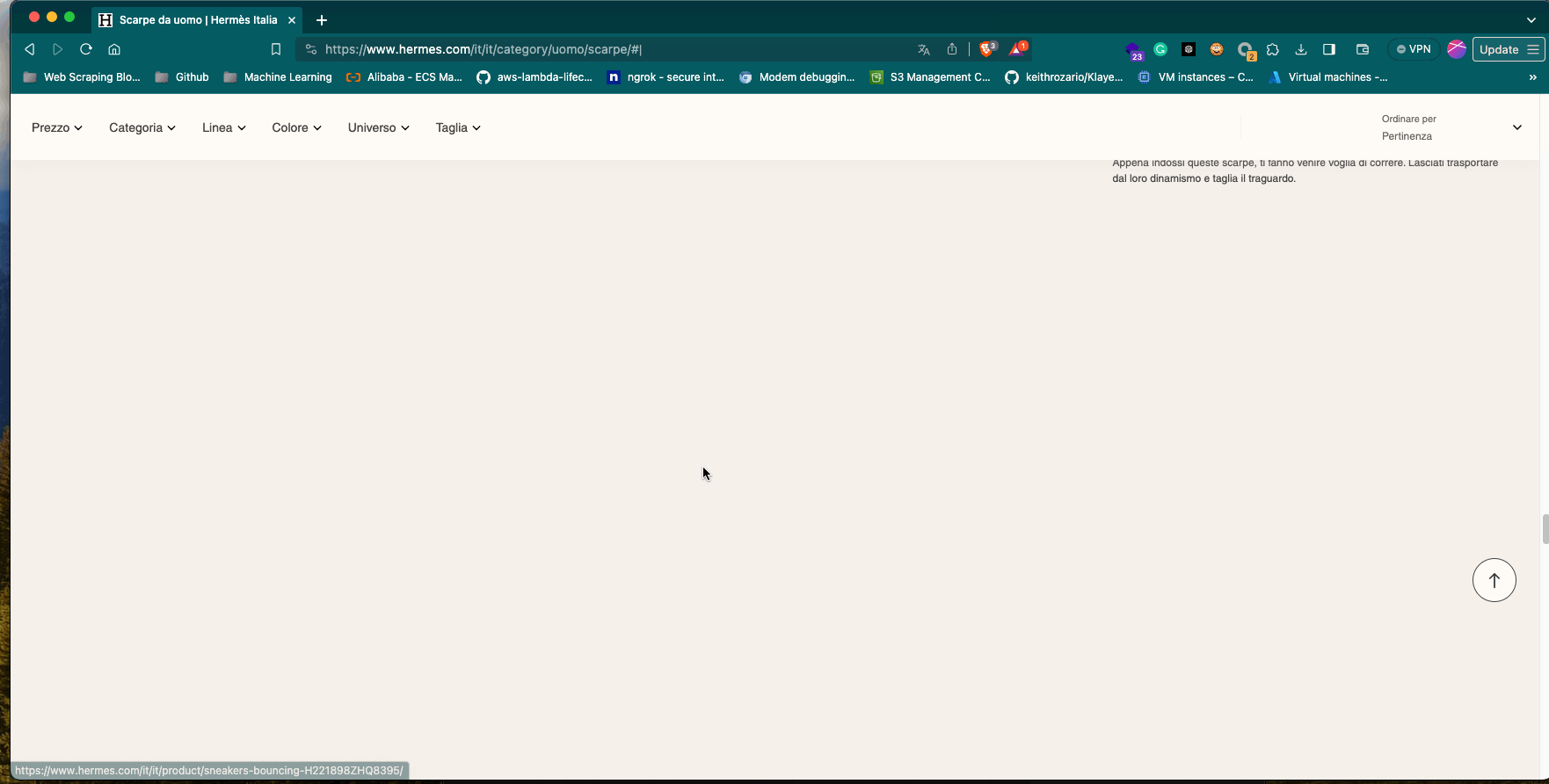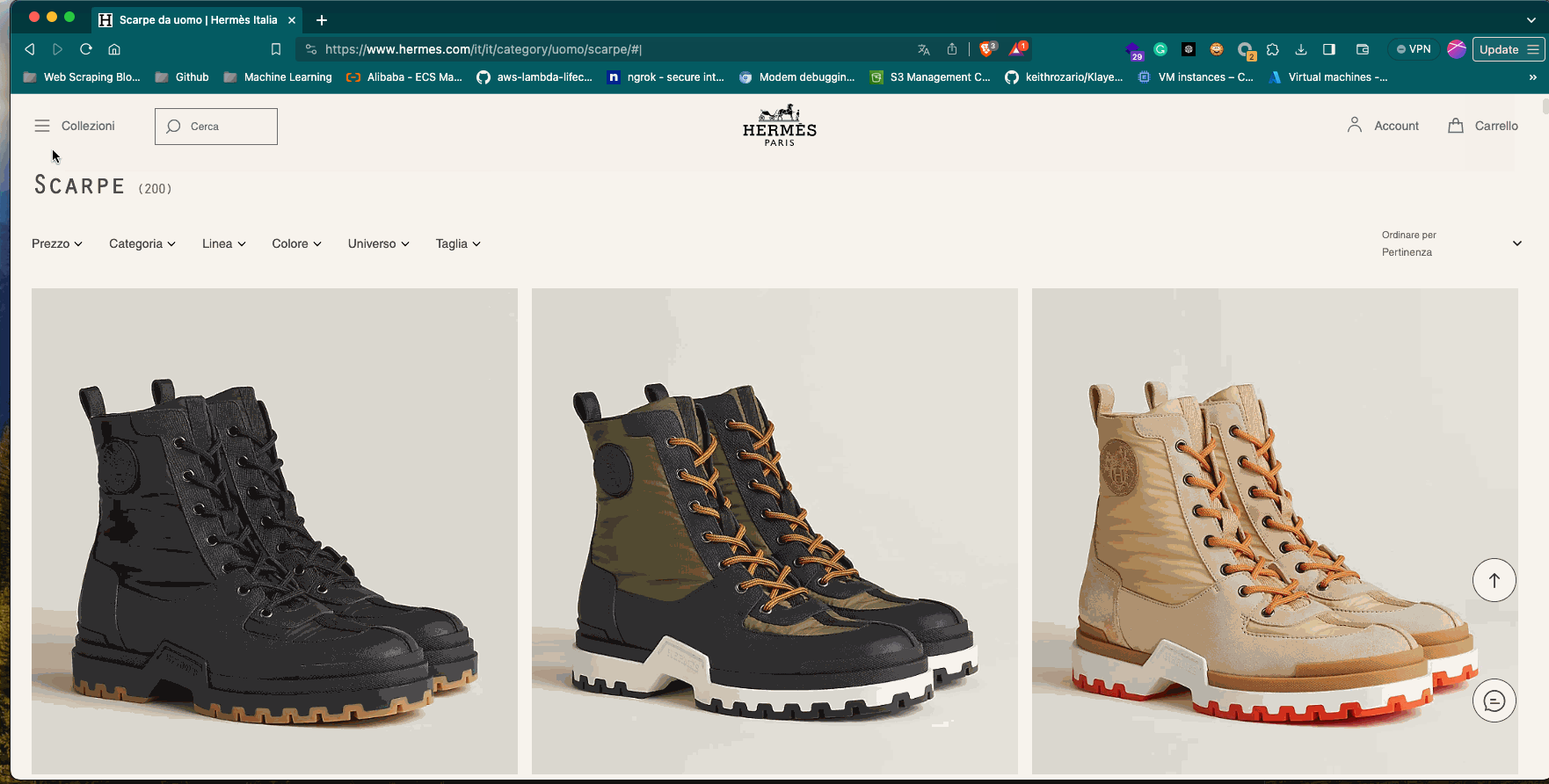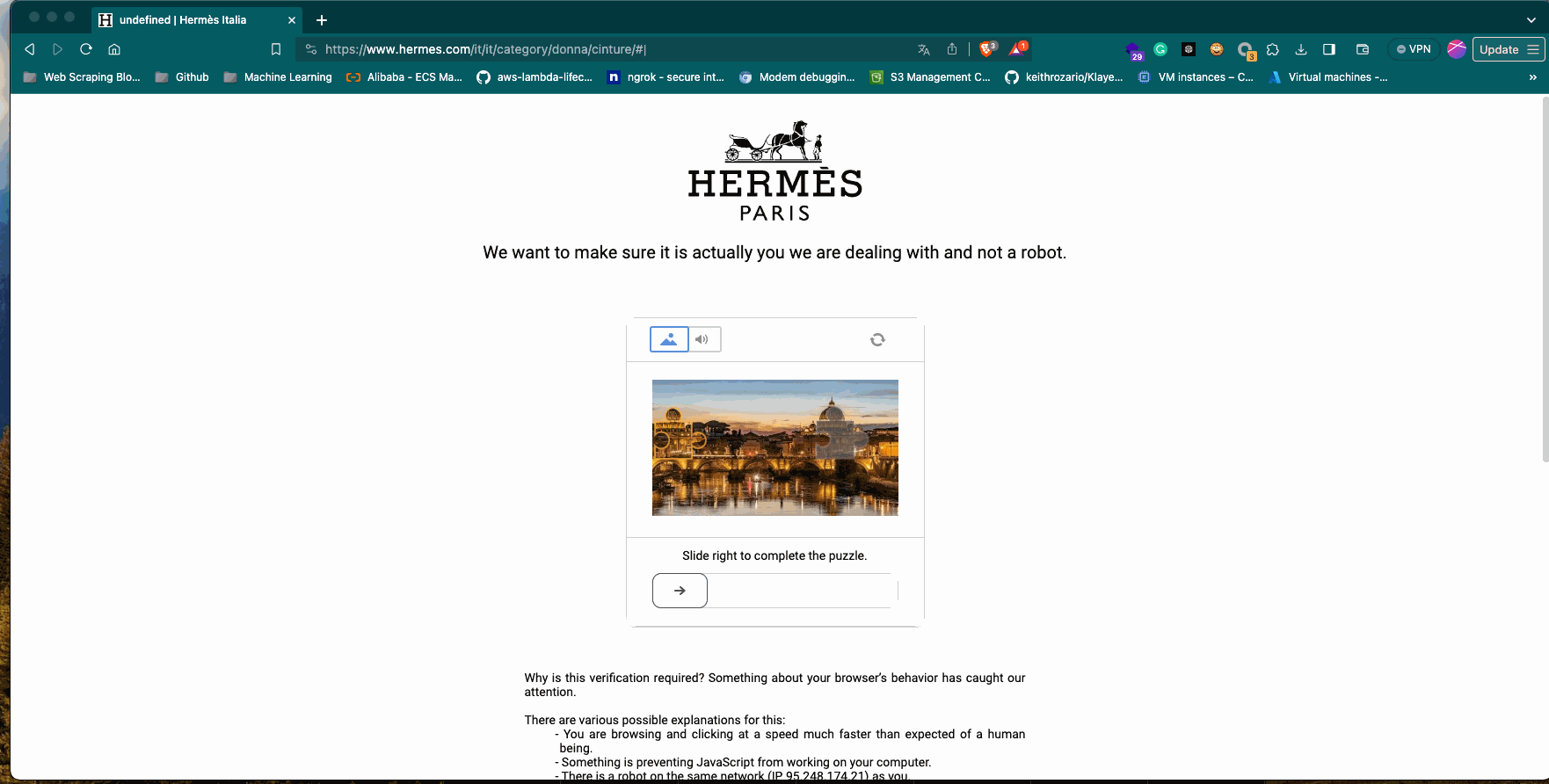
Datadome is one of the most advanced anti-bot solutions available on the market and, in my opinion, also the one that uses behavioral analysis in the most aggressive way. In fact, it’s not rare to be blocked by their CAPTCHA in the middle of a scraping session (but also in the middle of a human browsing session, which is not that good for the UX of websites).
[

{kind=link}
It uses all the most well-known techniques to detect bots, for example, TLS fingerprinting and AI, as mentioned before.
For this reason, starting a web scraping project when a website is protected with Datadome is always a lottery ticket, you won’t know until the end if you’ll be successful in scraping the data you’ll need.
It will depend on the setup of the solution on that particular website and this is true also for this article: I wanted to demonstrate I could scrape data from Footlocker UK, but I’m not sure I’ll be able to do it. Ready to discover it?
Disclaimer: all the techniques we’ll see in this article must be used in a legal and ethical way, without causing any harm to the target website. If you have some doubts about the legality of your web scraping project, have a look at the compliance guide and ask your lawyers any questions specific to your task.
First try: Scrapy-impersonate
There’s no need to waste time by trying to use traditional requests with Scrapy since they’re blocked 100% for sure by Datadome, but I wanted to try Scrapy-Impersonate, even if I’m not so confident that it will work.
2023-12-03 17:17:48 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://www.footlocker.co.uk/en> (referer: None) ['impersonate']
2023-12-03 17:17:48 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://www.footlocker.co.uk/en>: HTTP status code is not handled or not allowed
2023-12-03 17:17:54 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://www.footlocker.co.uk/en> (referer: None) ['impersonate']
2023-12-03 17:17:55 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://www.footlocker.co.uk/en>: HTTP status code is not handled or not allowed
2023-12-03 17:18:01 [scrapy.core.engine] DEBUG: Crawled (403) <GET https://www.footlocker.co.uk/en> (referer: None) ['impersonate']
2023-12-03 17:18:01 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://www.footlocker.co.uk/en>: HTTP status code is not handled or not allowed
2023-12-03 17:18:01 [scrapy.core.engine] INFO: Closing spider (finished)
I’ve looped three different browsers to impersonate, but it’s not working. We need to move on to the next idea.
Second try: Browser automation with Playwright
Let’s use a real browser to load the website and see if we can bypass the anti-bot protection.
def run_play(playwright: Playwright):
browser = playwright.chromium.launch_persistent_context(user_data_dir=USER_DIR, channel='chrome', headless=False,slow_mo=2000,args=CHROMIUM_ARGS)
page = browser.new_page()
url1='https://www.footlocker.co.uk/'
page.goto(url1, timeout=0)
interval=randrange(3,5)
time.sleep(interval)
url1='https://www.footlocker.co.uk/en/category/men/shoes.html'
page.goto(url1, timeout=0)
interval=randrange(3,5)
time.sleep(interval)
We have mixed results since we can load the first page but then, when we try to load the second one, there’s the Datadome CAPTCHA blocking us. It seems that the scraper is not detected as suspicious but its behaviour is.
Instead of opening the second page directly, which is not a standard behaviour for a human. In fact, after opening the home page, we’re usually moving our mouse around to navigate the website and we’re not writing down a new URL in the address bar.
For this reason, I’ll add the python-ghost-cursor package to the scraper and also residential proxies, since any more request from mine triggers the CAPTCHA.
Third try: Playwright + Ghost Cursor
Since I needed to add also proxies to my setup, I’ve chosen residential proxies located in UK, since I’m trying to get data from Footlocker.co.uk. In some previous scraping projects involving Datadome I’ve noticed the IP address location was something that made the difference in the success rates, but we’ll discover only later if this is enough.
The code became like this
def run_play(playwright: Playwright):
proxy={
"server": "MYPROXYPROVIDER",
"username": "USER",
"password": "PWD"
}
browser = playwright.chromium.launch_persistent_context(user_data_dir=USER_DIR, channel='chrome', headless=False,slow_mo=2000,args=CHROMIUM_ARGS, proxy=proxy)
page = browser.new_page()
url1='https://www.footlocker.co.uk/'
cursor = create_cursor(page)
page.goto(url1, timeout=0)
selector='#app > div.footlocker-web-app.FLUK.FL > header > nav > div.col.HeaderNavigation.HeaderNavigation__prominentSearch > div:nth-child(2) > button'
cursor.click(selector)
interval=randrange(5,10)
time.sleep(interval)
selector='#megaMenuDescription > div > div:nth-child(1) > ul > li:nth-child(1)'
cursor.click(selector)
interval=randrange(5,10)
time.sleep(interval)
I mostly use XPATH selector and I’m not sure they’ll work in the cursor package, so I needed to copy the CSS ones from the browser. They’re not the most reliable in the long run, especially the first one which concatenates many elements, but for this test they’re ok.
The good news here is that we can load the men’s shoes page! Let’s see if we can pass through all 38 pages of products and scrape the data from the whole product category.
I’ve added a loop and a data parsing to the scraper, so we can iterate on the different pages.
while check == 0:
html_page=page.content()
response_sel = HtmlResponse(url="my HTML string", body=html_page, encoding='utf-8')
website = 'FOOTLOCKER'
#print(response_sel.text)
products=response_sel.xpath('//li[contains(@class, "product-container")]')
for pdt in products:
try:
product_code = pdt.xpath('.//a[contains(@class, "ProductCard-link")]/@href').extract()[0].split('/')[-1].replace('.html', '')
except:
product_code=DEFAULT_VALUE #IF XPATH OR JSON FIELD DOES NOT EXIST, WRITE THE DEFAULT VALUE IN THE FIELD
try:
product_category = pdt.xpath('.//span[@class="ProductName-alt"]/text()').extract()[0]
except:
product_category=DEFAULT_VALUE
try:
fullprice = pdt.xpath('.//span[@class="ProductPrice-original"]/text()').extract()[0]
except:
fullprice = pdt.xpath('.//span[@class="ProductPrice"]/span/text()').extract()[0]
try:
price = pdt.xpath('.//span[@class="ProductPrice-final"]/text()').extract()[0]
except:
price = pdt.xpath('.//span[@class="ProductPrice"]/span/text()').extract()[0]
try:
currency = 'GBP'
except:
currency=DEFAULT_VALUE
country = 'GBR'
try:
product_url = 'https://www.footlocker.co.uk'+pdt.xpath('.//a[contains(@class, "ProductCard-link")]/@href').extract()[0]
except:
product_url = DEFAULT_VALUE
try:
brand = pdt.xpath('.//span[@class="ProductName-alt"]/text()').extract()[0]
except:
brand=DEFAULT_VALUE
with open("file_output_tmp.txt", "a") as file:
csv_file = csv.writer(file, delimiter="|")
csv_file.writerow([product_code,product_category,fullprice,price,currency,country,product_url,brand,website])
file.close()
try:
selector='#main > div > div.Page-body.constrained > div > div.main.col > div > div.SearchResults > nav > ul > li.col.Pagination-option.Pagination-option--next.col-shrink > a[aria-label="Go to next page"]'
cursor.click(selector)
interval=randrange(5,10)
time.sleep(interval)
except:
check=1
This works pretty well until we need to click to page 11, where the scraper returns to page 1. That’s a strange behavior, I’ve checked the next page selector several times and it’s correct and unique, just to understand that the website itself is broken and even when browsing normally it acts this way. WTF!
Anyway, despite this issue, the scraper seems to work! I could get all the items on the first 10 pages without being blocked and it was a great success.
The final challenge is to check if this solution works also from a datacenter, with a machine with a different device fingerprint.
Final: Playwright + Ghost Cursor + Brave Browser
After setting up an Ubuntu Virtual machine on AWS, I’ve launched the scraper but with not so much success.
The Browser APIs are exposing too many clues that the program is running from a datacenter, like the absence of a 3D card, a monitor, and speakers.
Without using external solutions, I’ve installed Brave Browser on the machine, which has embedded some anti-fingerprinting features. Even if some hints about the running environment could be seen, the success rate of my runs drastically improved.
On top of that, I needed to add the permission to use the geolocation of the browser to the website, since the popup was covering the selector I wanted to click.
The updated Playwright instruction becomes:
browser = playwright.chromium.launch_persistent_context(user_data_dir=USER_DIR, channel='chrome',executable_path='/usr/bin/brave-browser', headless=False,slow_mo=200,args=CHROMIUM_ARGS, proxy=proxy, permissions=['geolocation'])
As always, the full code can be found on The Web Scraping Club GitHub repository, available for paying readers. If you’re one of them but don’t have access, write me at pier@thewebscraping.club with your GH username.
Is it possible to bypass Datadome in 2023?
As we have seen, it’s not easy to bypass Datadome bot protection: it’s a complex solution that seems to work in mainly two aspects: traditional fingerprinting on different layers and behavioral analysis.
On top of that, its implementations may change from website to website, with different rules applied, so what we’ve seen today on Footlocker may be not enough for another website.
In my opinion, it remains the best anti-bot solution since it’s the most complex to bypass, but with the right tools and enough resources, as every solution around, it could be bypassed somehow.