How can I bypass Cloudflare Bot protection?
This is one of the most common questions I see in every community about web scraping I’m in, and this is completely understandable.
Cloudflare has the biggest market share for anti-bot solutions and many popular websites use it to protect their public data, so probably anyone approaching web scraping encountered it sooner or later.
[
{kind=link}
Example of Cloudflare Challenge
But the problem with this question is that it lacks context, and we’re seeing now what I mean.
Why is your scraper getting blocked?
I’ve recently written a more detailed post about this topic, but let’s summarize it.
In the first instance, we need to understand that not every Cloudflare installation is equal: some websites apply stricter policies while others are more permissive. So if you find a solution that works on a Cloudflare-protected website, this doesn’t mean that it will work also for others.
My suggested approach is to test your actual scraper using different external variables, like proxies and running environment, to understand which could be the cause of the block.
Testing different IP types
One quick test could be the following: is your scraper working when it runs from your laptop, using your residential connection (if you’re in an office building, you could try using your phone’s tethering)?
If this is the case but then the scraper doesn’t work when deployed on a server, we can move on to the next tests, but at least we understood that our scraper, if we’re lucky, could be enough.
Browserless or using browsers (and which one)
After the IP test, we can start making our ideas clearer.
If our scraper is browserless (let’s say a Scrapy spider with Scrapy-impersonate) and it works locally but not from a data center, we’re almost sure it’s a matter of IP reputation, so adding a residential proxy from an established provider could be enough. You can have a look at the offers reserved for our readers if you want to save some bucks.
If we’re using a browser automation tool like Selenium or Playwright in our project, there’s the chance that adding residential proxies could not be enough.
This is particularly true when facing anti-bot protections like Cloudflare, which uses browser and/or TLS fingerprinting to understand more about the device that’s making the request, so they can block suspect requests.
Depending on the rules applied to the anti-bot installation, their strictness level impacts also the range of free solutions we can apply.
The role of open-source in web scraping
Open-source plays a crucial role in web scraping: most of the tools widely adopted today are open-source projects, from Scrapy to browser automation tools like Playwright, Selenium, and Puppeteer.
As anti-bot measures evolved, more tailor-made and evolved tools came to life, like Undetected Chromedriver.
We need to say a huge “Thank You” to the open-source community that keeps releasing tools, trying to make our lives easier when doing web scraping, even if it’s not easy at all.
Companies like Cloudflare are investing millions in R&D to make their products more efficient and difficult to reverse-engineer, so keeping their pace can be extremely hard for programmers releasing free tools.
For this reason, in order to say thank you to valuable members of the open-source community who are maintaining key repositories in the web scraping community, I’m thinking about a secret project. If you work in a company willing to help the open-source community, please write me at pier@thewebscraping.club.
We would all love to have a silver bullet, for free, working for eternity, without the need to pay a penny for proxies or commercial solutions.
Unluckily, this is not available: this blog wouldn’t be here if web scraping was simple enough and reduced by using the same free power tool for all the websites in the world. Also, many web scraping professionals would not make a living if such a tool existed. And it’s a pity that some of the people approaching web scraping do not understand this.
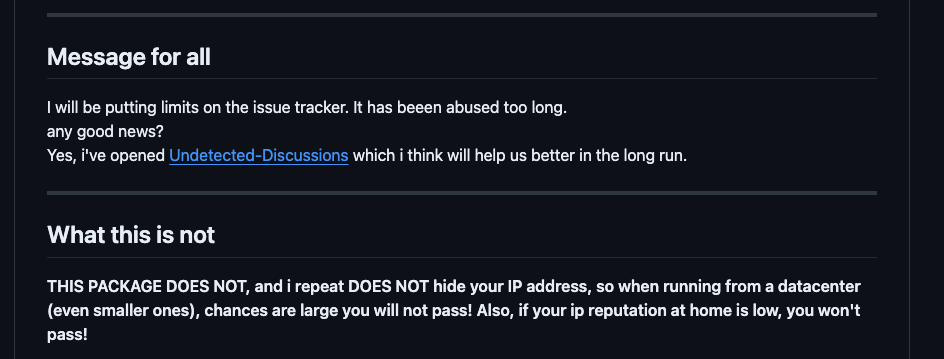
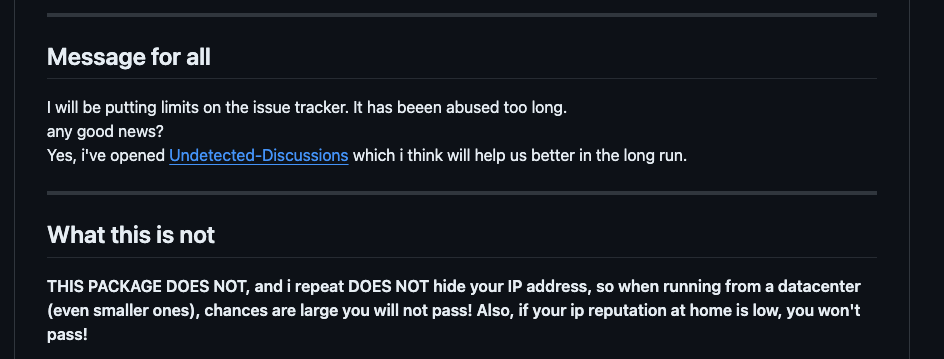
It makes me feel sad that a developer who spends time and passion creating open-source tools like Undetected Chromedriver needs to limit the issue section of the repository.
[
{kind=link}
Despite the instructions in the README, where the author clearly states that Undetected Chromedriver takes care only of the browser setup but that this is unuseful if a residential IP is not used, many issues opened are about challenges of anti-bots not bypassed. Some of these could be legit and could help the author improve the package, but others are opened by people who are still at the beginning of the web scraping learning curve.
We already tested a previous version of Undetected Chromedriver against the most famous anti-bot solutions, Cloudflare included, and we got mixed results.
TL;DR version: if you use it from your laptop you could (at least some months ago), it bypasses all the anti-bots tested, but if you run a scraper from a data center, even by adding a residential proxy, things are getting tougher. These results show that Undetected Chromedriver lacks the features of forging fake fingerprints based on real ones, just like anti-detect browsers do.
But what are the free alternatives we’ve got today to bypass Cloudflare?
I’ve selected three solutions that could help us in this task, keeping always in mind that the final results depend also on the running environment and the rules the single website applies.
If you want to have a look at some code, you can access the GitHub repository available for paying readers.
If you’re one of them but don’t have access to it, please write me at pier@thewebscraping.club to obtain it.
Scrapy Impersonate
We already talked about it in this article and still, it’s one of my favorite solutions I still use in a production environment.
Basically, it changes the TLS fingerprint of your Scrapy spider, in order to mimic a request made by a browser instead of a Python client.
Simple and effective, it allows us to keep our scrapers browserless, saving scraping time and the machine’s resources.
Implementation is straightforward, as you can see from the official repository page, and, according to the test results for the website chosen, it works pretty well.
CloudflareBypassForScraping
I’ve just discovered this package, which uses DrissionPage, a rewritten version of Selenium, which the author says is more efficient than the original one.
I’ve tested on the same website, Harrods.com, from my laptop, and it works, allowing me to open the web pages without being blocked.
Unluckily I was not able to test it on a data center for some errors I was not able to solve (and this is the reason why the publishing has been late this week).
You can find the code in the Repository, folder 49, if you want to test by yourself.
BrowserForge
Another way to bypass the browser fingerprinting of the anti-bot solution is to send to the server some altered data. so that it seems the browser is running on a consumer-grade device instead of a data center.
This is the typical approach of anti-detect browsers, which are specifically designed to accomplish this task.
If you want to know more about them, we recently wrote the first edition of the Anti-Detect Browser Royal Rumble, where we compare them using some well-known fingerprint tests.
If you prefer a DIY approach, instead, you can try using Browserforge, which we tested some weeks ago. It helps us in sending a fake fingerprint in our Playwright scrapers, giving us more chances to bypass Cloudflare.
From the tests we made in The Lab 46 (and reported also in The Lab 49), it seems that injecting a new fingerprint that changes the WebGL renderer is enough to bypass our test website, even if we’re running this scraper from a data center.
Of course, we must also add a residential proxy to the script, otherwise, we’d be immediately blocked because of its reputation.
Despite the growing challenges of bypassing anti-bot solutions, the open-source community is still more vibrant than ever in trying to find new ways to allow people to gather public data without relying on commercial solutions.
It’s not always an easy task and not every project is mature enough for a production environment. On top of that, usually, we need to assemble several tools together and sometimes it’s complex and time-consuming.
Understanding this, what we can do as end-users is to support these projects and help their contributors with constructive feedback and not complain about what’s not working.